Terracotta – Présentation
Dans cette première partie nous allons uniquement présenter Terracotta et dans une deuxième partie, probablement demain, nous présenterons des cas d’utilisation. Au cours de la dernière décennie, les systèmes informatiques ont enregistré une montée en charge foudroyante, et de nouvelles problématiques de scalabilité se sont posées. Aujourd’hui, les technologies standard (EJB, JMS, Jini) commencent à montrer leurs limites, tandis que le trafic réseau et les capacités de traitement des bases de données arrivent à saturation. Dans cet article, nous verrons comment Terracotta peut soulager vos architectures Java, grâce à son approche radicalement différente du clustering.
Problématique
Avant de présenter Terracotta, faisons un rapide tour des principaux problèmes rencontrés lorsqu’une application est victime de son succès. Nous prendrons ici l’exemple d’une application web.
Lorsque la charge augmente et qu’un unique serveur web ne suffit plus, il devient nécessaire de mettre en place un cluster, c’est-à-dire un agrégat de serveurs se répartissant le traitement des requêtes de manière transparente pour l’utilisateur. Pour assurer la sécurité des données de session des utilisateurs et améliorer la résilience générale du cluster, les serveurs disposent de systèmes de réplication. Mais ceux-ci souffrent de sérieuses limitations :
- Ils sont peu efficaces car ils reposent sur le mécanisme de sérialisation de Java, qui ne permet d’échanger que des objets complets, et pas de simples différentiels d’état.
- Ils saturent rapidement le réseau car le nombre de liaisons inter-serveurs augmente exponentiellement avec le nombre de serveurs.
Conscients de ces limitations et très sensibles à la sécurisation des données, les architectes estiment généralement plus prudent de stocker toutes les informations, mêmes temporaires, dans la base de données. Les architectures REST vont par exemple dans ce sens, en promouvant des couches de présentation totalement « stateless ». Mais cette décision a des impacts importants sur les performances : plus sûre mais infiniment moins réactive que la mémoire vive et supportant mal la mise en cluster, la base de données devient alors le principal goulet d’étranglement de l’application. Pour éviter les requêtes inutiles et conserver des performances acceptables, il est donc nécessaire de mettre en place des caches distribués, qui posent à leur tour des problèmes de réplication…
Le travail de l’architecte SI consiste donc à trouver le juste milieu entre la performance et la sécurité des données, tout en maîtrisant la charge des machines et la densité du trafic réseau. Voyons maintenant comment Terracotta peut aider à résoudre cette quadrature du cercle.

Présentation du produit
Terracotta est un middleware open-source gratuit pour Java de type NAM (Network Attached Memory). De la même manière qu’un NAS (Network Attached Storage) permet à plusieurs machines d’accéder aux mêmes fichiers sur un disque partagé, un NAM permet à plusieurs applications (ou plusieurs instances d’une même application) d’accéder aux mêmes graphes d’objets au sein d’une mémoire virtuelle partagée.
Afin de limiter le trafic réseau, Terracotta s’emploie à maintenir les données au plus près du code qui les utilise. Ainsi, lors qu’une application obtient un lock sur un sous-ensemble du graphe d’objet commun, ce sous-ensemble est monté (ou maintenu) au niveau de la JVM de l’application, qui y accède alors localement. Toute modification apportée aux objets est immédiatement répliquée sur le NAM pour des raisons de sécurité.
Pour toutes les problématiques de mise en cluster d’applications, de répartition de charge (datagrid) ou de distribution de données (caches), cette solution présente de nombreux avantages. Premièrement, le développement et la maintenance des applications en est fortement simplifié, puisqu’elles ne dépendent plus d’une API explicite pour s’échanger des données (JMS, RMI, SOAP…) : celles-ci peuvent être consultées et modifiées de manière transparente, comme si elles étaient disponibles localement. Ensuite, il n’y a plus besoin de répliquer préventivement les données : elles sont sécurisées au sein du NAM, et seront transmises, à la demande et de manière optimisée, aux seules applications devant y accéder. Enfin, ce système autorise la manipulation de structures qui seraient habituellement trop larges pour tenir dans la mémoire locale des applications : les informations nécessaires sont fournies en temps réel par le NAM.
Techniquement, Terracotta est composé de deux éléments :
- Un serveur indépendant chargé de la gestion de la mémoire partagée. Afin de garantir une reprise sur incident immédiate, toutes les données sont sécurisées de manière asynchrone dans une base de données interne (BerkeleyDB), et le serveur lui-même peut être mis en redondance active ou passive.
- Un « bootClassLoader » spécial qui instrumente la JVM des applications clientes et assure la liaison avec le serveur Terracotta. Un fichier de configuration « tc-config.xml » permet alors de définir quels graphes d’objets doivent être déployés sur le NAM (il est également possible d’utiliser des annotations).
La clusterisation est donc fournie comme un simple service d’infrastructure, qui ne nécessite aucune modification du code (d’ailleurs, vous ne verrez aucun extrait de code Java dans cet article) et aucun apprentissage particulier de la part des développeurs.
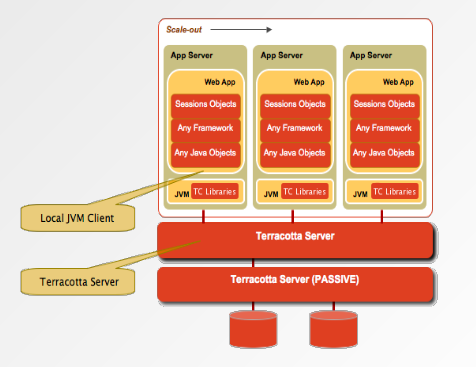
L’instrumentation de la JVM et des classes partagées autorise de nombreuses optimisations. Par exemple, contrairement au mécanisme de sérialisation qui transmet des objets complets, Terracotta travaille à un niveau plus fin et ne transmet que des différentiels, de manière compressée et par batches. Les applications instrumentées peuvent également être monitorées par la console d’administration de Terracotta, afin de suivre en temps réel l’état du cluster, le volume des données échangées, repérer les « deadlocks » distribués, etc.
Pour finir, Terracotta propose des modules d’intégration (TIM, Terracotta Integration Module), qui fournissent toute la configuration nécessaire pour s’intégrer aux principaux frameworks d’entreprise : Spring, Hibernate, EHCache, Struts…
Actuellement, Terracotta est déployé avec succès chez des grands comptes de la finance et des services (WalMart, Comcast, JPMorgan, Pearson…).
A demain pour les cas concrets d’utilisation.


Bonjour,
Merci pour cette présentation dans laquelle vous faites état de l’utilisation de BerkeleyDB par le serveur Terracotta.
Faut-il comprendre que Terracotta endosse les qualités d’une base de données (conforme à ce que représente BerkeleyDB) en plus d’être un middleware ? Le cas échéant, une extension à cet article exposant quelques approches générales (use case typiques) avec intérêts et limites pour lesquelles Terracotta est auto suffisant (c’est-à-dire sans recours à un sgbdr par exemple) serait fort intéressant.
BerkeleyDB n’est pas utilisé à proprement parler comme base de données.
C’est l’atomicité des opérations qui est intéressant.
En effet, il propose comme les bases de données de modifier les données de manière transactionnelle.
C’est ce principe qui permet de conserver la cohérence en cas de panne.
Bonjour,
Terracotta n’utilise BerkeleyDB que comme un moyen de persister l’état de la mémoire sur le serveur, afin d’assurer une reprise sur incident instantanée en cas de panne. Il ne se substitue donc en aucun cas à une base de données traditionnelle, qui conserve toute sa pertinence dans bien des cas d’utilisation (stockage des données métier, interrogation et reporting…).
Par contre, comme nous le décrivons dans cette série d’articles, le fait de pouvoir « monter » en mémoire les données de référence (souvent lues, peu écrites), quelle que soit leur taille (le facteur limitant traditionnel) permet de décharger considérablement le serveur de bases de données en éliminant tous les appels superflus.
Dans ce cadre, vous pouvez donc considérer Terracotta comme un gros cache distribué, et non un moyen de stockage pérenne des données métier.
Merci à vous deux pour vos réponses exprimant clairement ce que je ne supposais que vaguement, encore que, hier comme aujourd’hui, je n’imagine pour ainsi dire que des scénarios d’exploitation en back end pour la base de données « traditionnelle », ce qui m’amène au point pour lequel je n’ai par contre aucune intuition et sans doute d’autres derrière moi, qui est : dans quel « contexte » cette base de données est-elle alimentée de telle sorte qu’elle ne constitue pas le goulet d’étranglement que Terracotta se proposait « d’éliminer » ?
Je n’en suis qu’aux premiers chapitres de l’ouvrage « The defintive guide for Terracotta » qui laisse néanmoins entendre que pour certaines situations (sans doute développées plus loin dans le livre), une base de données ne serait pas implicitement nécessaire.
La réponse d’Olivier me laisserait plutôt penser que, dans la plupart des scénarios nécessitant de faire face aux contraintes qui nous conduisent à faire appel à des produits comme Terracotta, non seulement la base de données est impliquée dans le flux de production et qu’il s’agirait en effet pour Terracotta de soulager cette dernière afin que le goulet d’étrangement soit amoindri dans un rapport le rendant le plus « tolérable » possible. Si tel est le cas, cela annihile ma question en introduction de ce commentaire.
Pour ce qui est de voir Terracotta comme un cache, cela me laisse un peu perplexe quand à son bien fondé dans certaines situations. A titre d’exemple « simple » et concret tiré de la réalité, Terracotta est exploité entre autre dans le secteur du jeu dont des bookmakers. Je ne doute pas un instant que l’expertise et les choix effectués prouvent le bien fondé évoqué, pourtant la part de données souvent écrites me semble très conséquente dans leur contexte, je me demande donc si c’est vraiment du « cache » qu’ils trouvent la valeur ajoutée recherchée dans Terracotta.
Terracotta peut également servir de « tampon » entre le système et la base de données : les opérations effectuées en mémoire sont ensuite progressivement répercutées en base de données (« write-behind »), ce qui évite les pics de charge sur la base même.
Sinon, le livre existant est désormais relativement obsolète ; seuls les premiers chapitres sur les concepts généraux sont encore d’actualité. Je recommande donc d’attendre la nouvelle version, entièrement réécrite, qui doit sortir très prochainement.
Effectivement, je songeais à cette éventuelle faculté à gérer les « coups de feu » et c’est une question que je souhaitais poser, merci de me devancer :), et c’est intéressant, au point que je me demande si cela pourrait être envisageable d’exploiter une base non transactionnelle comme mongodb dans un contexte où les capacités transactionnelles sont parfois requises mais c’est une autre histoire.
Cependant, exposé ainsi, je retrouve le sentiment exprimé précédemment, à savoir que la base n’a pour principale vocation que des besoins de backend puisqu’on la décharge des responsabilités de production. Je dois passer à côté de quelque chose mais je ne vois pas trop quoi au juste finalement 🙂 la logique peut-être 🙂 qui m’apparait soudainement abstraite 🙂