
Storm – Ajouter du temps réel à votre BigData
Partie 1 – Introduction aux topologies, mécanismes et API
Par principe les traitements par batchs sont trop lents et la vision qu’ils nous donnent de nos données est dépassée de la réalité.
Storm est un système de calculs temps réel distribué et tolérant aux pannes. Développé à l’origine par la société BackType, le projet est devenu open-source après l’acquisition de la société par Twitter. Il est disponible sous licence Eclipse Public License 1.0. De plus, Storm est entré depuis quelques mois dans le processus d’incubation de la fondation Apache.
L’objectif de ce premier billet est de vous introduire les différents concepts et mécanismes mis en œuvres dans Storm.
Introduction aux topologies
Les concepts
Pour traiter en continu un ou plusieurs flux de données, Storm repose sur la définition d’une topologie. Une topologie prend la forme d’un graphe orienté acyclique dans lequel :
- Les Streams, symbolisés par les arcs, sont des séquences illimitées de Tuples. Un tuple est une liste de valeurs nommées qui représente le modèle de données utilisé par Storm.
- Les Spouts, nœuds racine du graphe, désignent les sources de streams. Il peut s’agir par exemple d’une séquence de tweets émis via l’API Twitter, d’un flux de logs ou encore de données lues directement depuis une base de données.
- Et enfin, les Bolts sont les nœuds qui consomment ces séquences de tuples émis par un ou plusieurs nœuds. Ils ont pour rôle de réaliser différentes opérations (filtres, agrégations, jointures, lecture/écriture vers et depuis une base de données, etc.) et si besoin d’émettre à leur tour une nouvelle séquence de tuples.

La figure, ci-dessus, illustre une topologie qui indexe dans Elasticsearch des tweets récupérés via l’API Twitter, calcule le nombre unique et total d’utilisateurs ainsi que le nombre de tweets émis par langue. Enfin, les statistiques sont stockées dans Redis.
Ainsi, chaque fois qu’un nouveau tweet est reçu il est immédiatement émis par le Spout vers chacun des Bolts ayant souscrit à son flux de sortie (stream). Le réseau ainsi formé par l’association de Spouts et de Bolts forme une topologie qui sera ensuite soumise au cluster Storm et exécutée sans interruption.
Regroupements de flux
Le regroupement de flux répond à la question suivante: lorsqu’un tuple est émis, vers quels bolts doit-il être dirigé ? En d’autres termes, il s’agit de spécifier la manière dont les flux sont partitionnés entre les différentes instances d’un même composant spout ou bolt. Pour cela, Storm fournit un ensemble de regroupements prédéfinis, dont voici les principales définitions :

- Shuffle grouping : Les tuples sont distribués aléatoirement vers les différentes instances bolts de manière à ce que chacune reçoive un nombre égal de tuples.
- Fields grouping : Le flux est partitionné en fonction d’un ou plusieurs champs.
- All grouping: Le flux est répliqué vers l’ensemble des instances. Cette méthode est à utiliser avec précaution puisqu’elle génère autant de flux qu’il y a d’instances.
- Global grouping: L’ensemble du flux est redirigé vers une même instance. Dans le cas, où il y en a plusieurs pour un même bolt, le flux est alors redirigé vers celle ayant le plus petit identifiant.
Storm fournit d’autres regroupements ainsi qu’une interface permettant d’implémenter ses propres regroupements.
Parallélisme d’une topologie
Mécanisme de parallélisation
Lorsqu’une topologie est soumise à Storm, celui-ci répartit l’ensemble des traitements implémentés par vos composants à travers le cluster. Chaque composant est alors exécuté en parallèle sur une ou plusieurs machines.
La figure suivante illustre la manière dont Storm exécute une topologie composée d’un Spout et de deux Bolts.

Pour chaque topologie, Storm gère un ensemble d’entités distinctes:
- Un « worker process » est une JVM s’exécutant sur une machine du cluster. Il a pour rôle de coordonner l’exécution d’un ou plusieurs composants (spouts ou bolts) appartenant à une même topologie. (NB: Le nombre de workers associés à une topologie peut changer au cours du temps.)
- Un « executor » est un thread lancé par un « worker process ». Il est chargé d’exécuter une ou plusieurs « task » pour un bolt ou spout spécifique. (NB: Le nombre d’exécuteurs associés à un composant peut changer au cours du temps.)
- Les « tasks » effectuent les traitements à appliquer sur les données. Chaque task représente une instance unique d’un bolt ou d’un spout.
Contrairement au nombre d’exécuteurs, le nombre de tâches pour un composant ne peut pas être modifié pendant toute la durée de vie d’une topologie.
Par défaut, Storm instanciera autant de tâches qu’il y a d’exécuteurs. C’est à dire, qu’une seule tâche sera alors exécutée par thread. Cette répartition correspond normalement au comportement recherché.
Cependant, il est possible de configurer un plus grand nombre de tâches. Dans ce cas, plusieurs tâches seront exécutées en série par un même thread. Le fait de provisionner plus d’instances, pour un même composant, offre par la suite la possibilité d’étendre le parallélisme d’une topologie sans l’arrêter mais aussi de garantir son bon fonctionnement en cas de perte d’un worker; on établit de manière générale que #threads <= #tasks.
Regardons maintenant comment configurer notre topologie.
Configuration
Storm expose un ensemble de paramètres pour configurer votre cluster ainsi que les topologies associées. Certains de ces paramètres sont des configurations système et ne peuvent pas être modifiés par une topologie. D’autres spécifient le comportement des topologies exécutées et sont donc modifiables par topologie. Chacun de ces paramètres possède une valeur par défaut définie dans un fichier config/default.yaml; ce dernier est inclus de base dans toute distribution Storm.
Tout d’abord, il est possible de surcharger ces valeurs en créant un fichier config/storm.yaml. Vous pouvez créer un fichier différent pour chaque machine et ainsi ajuster vos paramètres en fonction de la puissance de calculs dont vous disposez.
Storm offre ensuite la possibilité de définir une configuration par topologie au moyen de la classe backtype.storm.Config disponible depuis l’API Java. La configuration est alors soumise au cluster en même temps que la topologie. Remarquez que seuls les paramètres préfixés par TOPOLOGY peuvent être surchargés par une topologie.
Voici quelques options qu’il est possible de modifier:
- TOPOLOGY_WORKERS : Définit le nombre de workers à créer pour une topologie
- TOPOLOGY_DEBUG : Indique à Storm de logger chaque message émis.
Pour chacune de ces options il est possible d’utiliser directement les méthodes Config#setNumWorkers et Config#setDebug
Enfin, l’API Java permet de spécifier une configuration par composant afin de paramétrer leur niveau de parallélisme (parallelism hint) des spouts/bolts. Ce paramétrage peut se faire des deux façons suivantes :
– Interne: En surchargeant dans votre Spout ou Bolt la méthodegetComponentConfiguration puis de retourner la Map correspondant à votre configuration.
– Externe: En utilisant les méthodes exposées par les implémentations de l’interface ComponentConfigurationDelacarer retournées par les méthodes setBolt et setSpout du TopologyBuilder.
Pour finir, Storm prendra par ordre de préférence les configurations suivantes: default
s.yaml < storm.yaml < topologie < composant interne < composant externe
Une API Java simple garante du traitement des messages.
Storm fournit une API Java simple non seulement pour implémenter les composants nécessaires à l’exécution de la logique métier d’une topologie. Mais aussi pour s’assurer que tous les tuples émis seront aux moins traités une fois.
Les interfaces des différents composants
Le diagramme ci-dessous représente l’arborescence des principales interfaces/classes permettant de modéliser une topologie.
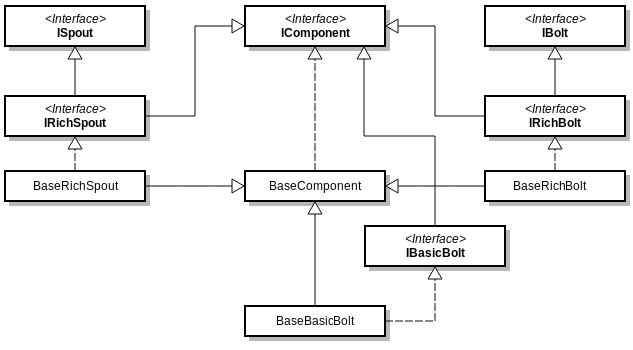
Pour commencer, IRichBolt et IRichSpout sont les deux principales interfaces utilisées pour implémenter des Spouts/Bolts en Java.
IComponent
L’interface IComponent expose les méthodes nécessaires à l’utilisation de l’API Java. Ces dernières sont utilisées directement par l’API Storm lors de la construction et configuration d’une topologie depuis une instance TopologyBuilder.
public interface IComponent extends Serializable {
void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer);
Map<String, Object> getComponentConfiguration();
}
– D’une part, chaque composant doit déclarer le schéma des tuples émis depuis l’objet OutputFieldDeclarer, passé en argument de la méthode declareOutputFields. D’autre part, il est possible de définir des paramètres spécifiques en surchargeant la méthode getComponentConfiguration.
ISpout
Les méthodes héritées des interfaces ISpout et IBolt sont, quant à elles, invoquées directement par Storm après soumission de la topologie au cluster. Elles exposent l’ensemble des méthodes appelées au cours du cycle de vie de notre topologie.
public interface ISpout extends Serializable {
void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector);
void close();
void nextTuple();
void ack(Object o);
void fail(Object o);
}
– Storm commence par appeler la méthode open pour initialiser une instance de spout. Cette méthode permet notamment de récupérer l’instance SpoutOutputCollector utilisée ensuite pour émettre des tuples.
– Il invoque ensuite en continu la méthode nextTuple pour ordonner à la tâche d’émettre son prochain tuple au moyen du SpoutOutputCollector. Pour ne pas surcharger la consommation CPU, il est d’usage d’endormir le thread (quelques millisecondes) lorsqu’il n’y aucun tuple à émettre.
– Et enfin, la méthode close est invoquée lorsqu’un Spout est sur le point d’être arrêté. En production, il n’y a cependant aucune garantie qu’elle soit appelée, notamment dans le cas où le worker exécutant la tâche est tué (kill -9). Néanmoins, elle est principalement utile lorsque vous arrêtez une topologie exécutée avec un cluster en mode local.
IBolt
public interface IBolt extends Serializable {
void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector);
void execute(Tuple tuple);
void cleanup();
}
– L’initialisation d’une instance associée à un Bolt s’effectue via la méthode prepare. De la même manière que pour un Spout, Storm fournit un OutputCollector pour émettre des tuples.
– La méthode execute permet ensuite de traiter les tuples reçus en entrée. De manière générale, la logique métier de notre bolt sera exposée via cette méthode. Par ailleurs, il n’est pas obligatoire qu’un tuple soit immédiatement traité après réception.
– Enfin, la méthode cleanup est identique à la méthode close de l’interface ISpout.
Fiabilité du traitement des messages
Quand un tuple est-il complètement traité ?
Un tuple émis par un spout a de grandes chances d’entraîner l’émission de plusieurs nouveaux tuples dès lors qu’il est traité par une tâche bolt. Par exemple, un tuple A peut entraîner la création d’un tuple B et C qui entraînerons à leur tour la création d’un tuple D et E. Le tuple racine et ses tuples fils forment alors un arbre de messages.

L’API Storm garantit que chaque tuple émis depuis un spout sera au moins une fois « complètement traité ». Storm désigne un tuple racine comme étant « complètement traité » dès lors que les n-tuples qui composent son arbre de messages ont été traités avec succès. A l’inverse, il sera considéré en échec s’il n’est pas traité dans un laps de temps imparti. Par défaut, ce timeout est défini à 30 secondes et peut être modifié spécifiquement pour une topologie.
Pour indiquer à storm qu’un tuple doit être traqué, il faut lui associer un identifiant lors de son émission :
spoutOutputCollector.emit( new Values("field1", “field2), messageId);
Storm se chargera ensuite de suivre l’arbre de messages qui sera créé. Lorsque le tuple sera identifié comme étant « complètement traité », la méthode ack de la tâche spout d’origine sera invoquée et l’identifiant du message sera passé en argument. En règle générale, une implémentation de cette méthode a pour rôle de supprimer le message d’origine de la source de données afin de ne pas l’émettre à nouveau. Au contraire si le traitement du tuple échoue alors la méthode fail sera appelée. Le spout pourra alors réémettre le tuple.
Ancrage et acquittement d’un tuple
Afin de bénéficier de ce mécanisme, il est nécessaire dans un premier temps d’indiquer à Storm lorsqu’une nouvelle branche est créée dans l’arbre de tuples. Cette première étape, appelée ancrage, consiste à spécifier au sein d’une tâche bolt le ou les tuples entrants auxquels le tuple émis doit être rattaché. Ainsi, si le tuple émis échoue, vous serez en mesure de rejouer le tuple racine.
this.outputCollector.emit(inputTuple, new Values("field1", "field2"));
A l’inverse, il est possible d’émettre un tuple sans ancrage selon le niveau de garantie attendu dans votre topologie.
this.outputCollector.emit(new Values("field1", "field2"));
Cependant, si par la suite le tuple échoue alors il ne sera pas possible de rejouer le tuple racine puisque storm ne notifiera pas le spout d’origine via sa méthode ack.
Dans un second et dernier temps, il est nécessaire d’indiquer à storm quand un tuple a été traité individuellement; cette dernière étape est appelée acquittement. Pour ce faire, nous utilisons les méthodes ack et fail de l’OutputCollector. Pour rappel, storm nous fournit cette instance lors de l’appel à la méthode prepare d’un bolt.
this.outputCollector.ack(tuple); ou this.outputCollector.fail(tuple);
Lorsqu’un tuple n’est pas acquitté il est automatiquement considéré en échec après 30 secondes et le tuple racine est alors rejoué. Mais il peut être utile dans certains cas, par exemple après avoir attrapé une exception, de rejouer immédiatement le tuple d’origine. Pour cela, il est possible d’utiliser la méthode fail.
Pour mieux comprendre le mécanisme d’ancrage et d’acquittement intéressons- nous au cycle de vie d’un tuple.
Les Ackers
Pour traquer la complétion des tuples émis depuis les tâches spout, storm instancie pour chaque topologie un ensemble de tâches appelées ackers. Par défaut, le nombre d’ackers est fixé à 1 mais peut être modifié pour les topologies générant un grand nombre de messages.
Le schéma ci-dessous illustre le rôle que jouent les ackers dans l’algorithme mis en place par storm.

La soumission d’un tuple depuis un spout ou un bolt se traduit dans storm par l’envoi d’un message associé à un identifiant aléatoire de 64 bits (1). Ces identifiants sont ensuite utilisés par les ackers pour suivre l’état de chaque arbre de tuples.
(2) Lors de l’émission d’un nouveau tuple depuis un bolt, les identifiants des tuples racines sont recopiés depuis le tuple ancré vers le nouveau tuple. Si bien que, chaque tuple connaît l’ensemble des identifiants des tuples racines de leur arbre de messages.
Puis, lorsqu’un tuple est acquitté, un nouveau message est envoyé à l’acker avec les informations liées aux modifications de l’arbre (3); c’est à dire les identifiants des nouveaux tuples et des tuples traités. Storm prend alors connaissance de son état et détermine s’il est complété ou non. Puisque l’état de l’arbre n’est connu qu’à l’acquittement il ne peut donc pas être prématurément complété.
Pour autant, toute la force de l’algorithme de Storm repose dans le fait que l’état de chaque arbre n’est pas stocké à proprement parlé par les ackers. Au lieu de cela, et pour ne pas accentuer la consommation mémoire, un acker maintient une map associant l’identifiant d’un tuple spout à une paire de valeurs. La première valeur correspond à l’identifiant de la tâche spout ayant soumis le tuple et est utilisée pour envoyer le message de complétion. (4) La deuxième valeur appelée « ack val » est le résultat d’un XOR sur les identifiants des tuples créés et acquittés de l’arbre. Ainsi quand la « ack val » passe à 0 l’arbre est identifié comme étant complètement traité (7).
Cas d’erreurs système
Pour finir, intéressons-nous maintenant aux différents cas d’erreurs qui peuvent survenir lors de l’exécution d’une topologie et comment les mécanismes de storm permettent qu’aucune donnée ne soit perdue.
On distingue les trois cas d’erreurs suivants:
- Une tâche bolt s’arrête avant d’avoir pu acker un tuple : Aucun ack ne sera réalisé avant le timeout, le tuple sera alors automatiquement réémis.
- La tâche acker s’arrête : L’ensemble des tuples gérés par cet acker sera alors mis en échec.
- La tâche spout s’arrête : Dans ce dernier cas, storm ne fournit pas nativement de solution. La source de données utilisée par le spout est alors responsable de rejouer le message.
Architecture d’un cluster
Cycle de vie d’une topologie
Cluster mode
Une topologie est soumise au cluster via Nimbus. Nimbus est le nom donné au nœud maître d’un cluster storm. Il est responsable de distribuer le code à travers le cluster, d’assigner les tâches aux workers nodes et enfin de monitorer les erreurs. Ensuite, les workers nodes sont chargés d’exécuter des daemons appelées Supervisors. Chaque supervisor écoute les tâches assignées à sa machine puis démarre et stoppe des « worker processes » en conséquence. Enfin, comme nous l’avons vu précédemment chaque « worker process » exécute un sous-ensemble d’une topologie.
Storm s’appuie ensuite sur Apache Zookeeper pour coordonner les échanges entres nimbus et les supervisors ainsi que pour stocker l’état du cluster afin de rendre les daemons stateless et fail-fast. De cette manière, si le daemon Nimbus ou un des Supervisors venait à s’arrêter il serait automatiquement redémarré par l’instance Zookeeper.

Storm utilise nativement la librairie ZeroMQ pour la communication inter-worker, c’est à dire de nœud-à-nœud. Depuis la version 0.9.0 il est possible d’utiliser Netty comme implémentation offrant ainsi une alternative purement Java à 0MQ. Puis la librairie LMAX Disruptor pour les échanges intra-worker; c’est à dire de thread à thread au sein d’un même nœud. Enfin, Storm ne fournit aucun mécanisme pour faire communiquer plusieurs topologies ensemble.
Pour exécuter une topologie en mode cluster (production), il est nécessaire de passer par le client storm, d’une part pour démarrer les daemons de la manière suivante:
- $ storm/bin/storm nimbus
- $ storm/bin/storm supervisor
Et d’autre part pour soumettre la topologie en spécifiant le chemin vers notre jar, la classe main ainsi que les éventuels arguments.
$ storm/bin/stormstorm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3
A l’exécution de la commande storm jar le code est distribué à travers le cluster.
Pour ensuite arrêter une topologie, il suffit d’exécuter la commande storm kill en passant en argument le nom de notre topologie.
Local mode
Pour faciliter le développement et les tests, il est possible d’exécuter une topologie en mode local. Le fonctionnement est identique au mode cluster.
Storm UI
Enfin, il vous est possible de monitorer votre cluster via Storm UI en exécutant la commande storm ui. L’application est ensuite disponible à l’adresse http://localhost:8080.
Cette interface est un bon point d’entrée pour tester votre configuration et analyser les effets positifs ou négatifs d’une configuration sur le cluster. Elle fournit des informations sur les erreurs provoquées par les tâches, le débit ainsi que les performances de latence de chaque composant de chaque topologie en cours d’exécution.
Conclusion
Pour finir je vous invite à visiter le site Storm Wiki ainsi que le Tutorial officiel sur Github pour de plus amples informations.
Dans le prochain article nous verrons, entre autre, comment implémenter la topologie illustrée dans ce premier billet. Merci à vous et n’hésitez pas à me faire part de vos remarques.
Références
Storm Tutorial
Blog Michael. G. Noll
Slideshare
Storm Real-Time Processing Cookbook de Quinton Anderson

