
Apache Zookeeper: facilitez vous les systèmes distribués
Vous (ou votre client) avez besoin de coder un site web en Java. Il ne vous viendrait pas à l’idée d’écrire un serveur d’application en entier, en partant des sockets. De la même manière, si vous avez besoin d’écrire une énorme application distribuée, vous n’allez pas coder tous vos algorithmes de gestion des verrous, de messages, ou vos annuaires de services. Vous utiliserez Zookeeper de la fondation Apache. Le but de cet article est de vous présenter cet outil.
Pour toi qui ne connait pas forcément les systèmes distribués
On est tout à fait conscient que tout le monde ne connait pas sur le bout des doigts les problématiques des systèmes distribués. Alors, voici quelques rappels : Un système distribué, fondamentalement, consiste en plusieurs machines connectées entre elles et qui résolvent ensemble un problème, par opposition avec un système centralisé, donc une grosse machine unique qui prend tout à sa charge. Le cas d’école est Google, pour lequel aucune machine unique ne saurait traiter toutes les requêtes. Un bon exemple de l’usage qu’on peut en faire est décrit . Le simple fait d’avoir plusieurs machines qui doivent travailler ensemble est une source non négligeable de problèmes, parmi lesquels :
- La résistance aux pannes : si une machine tombe en panne dans le réseau, que faire ? Si elle est la seule à porter des informations importantes, celles-ci sont perdues. Dans ce cas, on règle la question avec la redondance des informations, dupliquées sur plusieurs machines.
- La consistance de l’information, en particulier si elle est dupliquée. Le but est d’offrir une indépendance de la valeur de la donnée par rapport à sa source : on veut éviter que chaque machine porte une version différente, donc surement obsolète, d’une information dont on a besoin.
- La répartition de la charge : comment bien gérer ses ressources pour éviter qu’une seule machine ne soit trop sollicitée, alors que les autres sont inactives ?
- Comment une requête émise par un client est-elle traitée ? Qui le fait ? Et comment garantir que le résultat est le bon, indépendamment de la machine qui a traité la question ? C’est le problème dit du consensus : on dit qu’il y a consensus si deux machines ayant les mêmes données initiales donnent le même résultat pour le même traitement.
La liste ci-dessus n’est pas exhaustive, mais il est important de comprendre qu’il s’agit d’un problème fortement non trivial, sur lequel des esprits brillants se sont penchés pendant des années. Ces questions sont donc connues, et il existe des techniques de programmation et des patterns pour y faire face. Ainsi, il est hors de question de redévelopper soi-même son propre système. Ce qu’on attend d’un framework qui prend en charge une telle architecture est :
- La communication entre les instances (ou machines. Mais si vous voulez faire impression dans une soirée technique, parlez de nœud ou d’instance). Par exemple, vous voulez envoyer un message à un ensemble d’instances (un cluster) pour lancer un traitement. Vous avez aussi besoin de savoir si une instance est opérationnelle, par exemple. Pour bien communiquer, une méthode utilisée consiste en une queue. Celle-ci permet d’envoyer des messages directement ou par sujet, de les lire de manière asynchrone, etc. La communication, exactement comme en local avec plusieurs processus, passe par la coordination dans l’usage des ressources. Concrètement, quand un nœud écrit sur un fichier, il est préférable qu’il pose un verrou, visible par tous les autres nœuds, sur le dit fichier.
- Un système de fichiers distribué : on ne souhaite pas savoir que tel fichier est sur l’instance machin. On veut avoir l’illusion de manipuler un unique système de fichiers, exactement comme sur une seule machine. La gestion de la répartition des ressources, avec ce qu’il faut faire si une instance ne répond pas, n’est pas utile à savoir.
- Un service de nommage : pour le présenter, certes de manière approximative, on aimerait une sorte de Map<String,Object> qui soit répartie sur le réseau, que toutes les instances puissent utiliser. Un exemple type serait JNDI. Le but du service de nommage consiste à avoir un système distribué d’accès aux objets.
- Un système robuste de traitement des requêtes : imaginons une architecture répartie qui accueille des ordres boursiers en temps réel. On n’est pas à l’abri d’une instance qui ne répond pas, ou d’une connexion réseau qui échoue. Dans ce cas-ci, l’ordre est perdu, la transaction n’est pas réalisée, un trader ne touche pas sa commission, et vous recevez un coup de fil peu aimable dans la minute. Ce n’est pas souhaitable, et il serait bien que le système soit assez robuste pour faire face à une défaillance locale. Plusieurs modèles (commit en deux temps, en trois temps, algorithme de Paxos) ont été soumis. Il en ressort que l’on peut donner des rôles à des instances : leader d’un traitement métier, ou follower. Le premier, pas forcément unique, ordonne et supervise un traitement. Le second, pas unique, calcule le résultat. Si le leader fait défaut, un autre prend la relève. Plusieurs followers sont sollicités pour parer au défaut de l’un d’eux. Toujours la même idée : la redondance créé de la robustesse.
Qu’offre Zookeeper ?
Si vous suivez ce blog de manière assidue, le nom vous sera déjà familier parce qu’Apache Storm utilise Zookeeper pour ses nœuds ( source: ). Le projet ne se réduit pas à une brique de Storm, il sert à résoudre toute une famille de problèmes qu’on aura forcément dans la conception d’un système distribué :
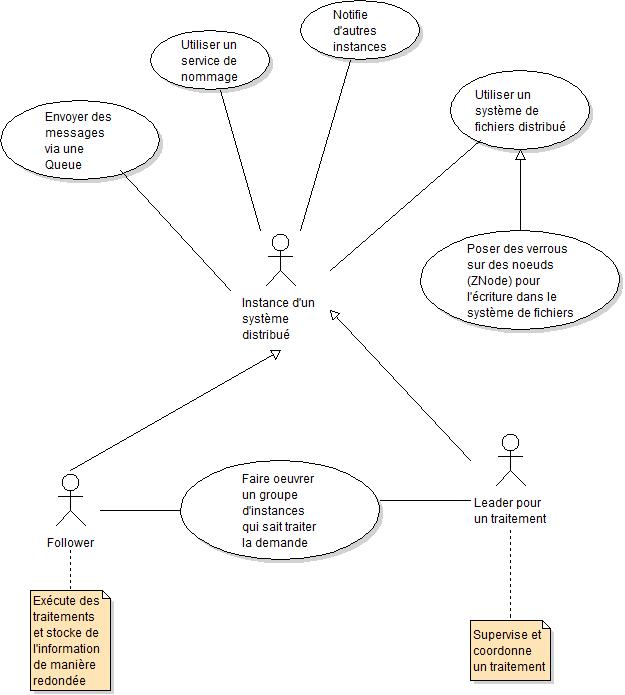
Travailler avec un système distribué pose un certain nombre de problèmes qui sont pris en charge par Zookeeper (dont c’est, au fond, la raison d’être) :
- Des instances reçoivent des traitements à exécuter, et le traitement doit finir. Cela veut dire qu’il faut en plus un système robuste et résistant aux pannes. Pour cela, pas de secret, Zookeeper utilise un système de gestion de nœuds redondants qui réduit considérablement la probabilité d’échec. En substance, un leader demande à un groupe (le quorum) de followers de traiter la requête. Zookeeper implémente une solution pour que le leader soit remplacé s’il est défaillant, et le groupe de followers est suffisamment vaste pour gérer la panne d’un des nœuds, et donc, avoir une réponse. En conséquence, plus d’instance améliore drastiquement la résistance aux pannes…
- Pour réaliser ces traitements, ces instances communiquent sur un système de fichiers commun, dit système de fichiers distribué. Zookeeper en propose une version hiérarchique dont les nœuds sont des ZNodes, avec authentification au besoin. Coordonner la lecture et l’écriture est un problème qui se règle avec l’utilisation de verrous.
- Ces instances ont besoin de s’échanger des informations par un moyen direct. Une queue est mise en place pour l’envoi de messages, et il est possible de notifier des nœuds.
- Ces instances ont besoin d’accéder à des objets partagés, et nommés. C’est précisément le rôle d’un service de nommage.
Pourquoi Zookeeper est-il plus fiable ?
Zookeeper utilise plusieurs grandes idées pour garantir que la panne de nœuds n’affecte pas le système dans son ensemble. Sur le principe,
il définit son propre algorithme, le Zookeeper Atomic Broadcast en se basant sur l’algorithme de Paxos qu’il améliore. La première question qu’on a envie de poser est celle du consensus : on souhaite que toutes les instances sollicitées répondent la même chose si elles ont la même donnée initiale. En 1985, tout espoir s’envole avec le théorème de Lynch, Fisher et Paterson : c’est impossible dans le cas général. L’algorithme de Paxos garantit une forme de consensus, ce qui est aussi le cas chez Zookeeper. Il y a plusieurs grandes étapes :
- Un client soumet une requête
- Un nœud leader est élu et se charge de la requête. L’élection se base sur un numéro de version : le nœud qui a le plus élevé est considéré comme leader.
- Le leader demande à un ensemble de followers (ensemble appelé quorum) leur aide pour traiter le problème. Les followers reçoivent donc une demande et répondent au leader. Si celui-ci ne répond pas, un nouveau leader est choisi. Ainsi, on évite que le leader ne devienne un SPOF, c’est-à-dire un Single Point of Failure.
- Le leader établit une connexion point à point avec chaque élément du quorum et leur soumet la requête. L’intérêt d’avoir tout un quorum à disposition est que si un nœud du quorum ne répond pas, les autres peuvent réussir à le faire.
- Le quorum envoie le résultat au leader. Celui-ci envoie l’ordre de fin de traitement (commit). Le consensus est respecté, le résultat est utilisable.
Comment s’en servir ?
La classe principale, celle qui porte la grande majorité des opérations utiles, est Zookeeper. Les main sont là pour lancer les instances en fonction de leur rôle.
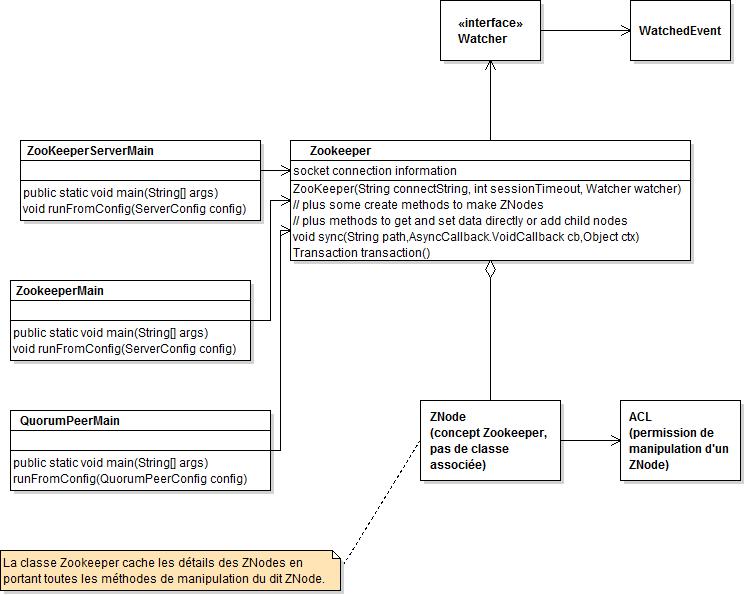
En Zookeeper, tout est fichier
Conceptuellement, le système de fichier est structuré comme un arbre. Chaque nœud porte un nom contenant des / et suivant le principe de hiérarchie : / est le nœud racine, /zksupernode un de ses enfants et /zksupernode /zknode un enfant de l’enfant. Les nœuds ont un double rôle : ils portent du contenu et peuvent avoir des enfants. Les permissions sont gérées par les ACL (AC pour access control). En résumé, Zookeeper propose un système de fichier hiérarchique. Il existe deux types de nœuds : les nœuds persistants et les nœuds éphémères. Les premiers, comme leur nom l’indique, survivront au traitement en cours. Les seconds sont plus utiles comme fichier de travail pendant une session, et sont ensuite perdus.
Mais où sont les classes Queue et Lock ?
Eh bien, autant vous le dire tout de suite, il n’y en a absolument pas, parce que tout est géré par des ZNodes ayant des noms particuliers ! Autrement dit, le système de fichiers est la base de la gestion des verrous et de queues. En effet, sur la gestion des queues, il suffit de créer un ZNode dont le nom termine par queue-M avec M un nombre relatif à la priorité. De même, un nom de ZNode avec read- créé un verrou en lecture, et on utilise write- pour un verrou en écriture.
Tout est fichier : choisir un leader
Parler du processus d’élection du leader est un excellent exemple d’utilisation des conventions de nommage sur les nœuds. L’algorithme se décrit en pseudo-code comme suit, à partir d’un chemin absolu ELECTION dans les ZNodes. Pour qu’un nœud demande le rôle de leader, il déroule les étapes suivantes :
- Création d’un ZNode séquentiel et éphémère ayant comme chemin « ELECTION/n_ » où n est un numéro servant de numéro de version de la demande, en substance.
- Les nœuds ELECTION/n_i vont être créés par les prétendants pour avoir le rôle de leader. La valeur de i suit une séquence croissante.
- Le leader est celui qui a créé le nœud avec le numéro le plus élevé.
- En général, on utilise un autre nœud pour dire qu’un leader a été choisi et que celui-ci commence un traitement.
Apache Curator : le complément indispensable
![]()
Netflix a développé les bases d’une API de plus haut niveau sur Zookeeper, et le projet est passé dans l’incubateur d’Apache, il s’agit d’Apache Curator (actuellement en version 0.7, mais son usage par Netflix lui confère une certaine légitimité).
L’apport de cette API est de faciliter l’usage de Zookeeper en fournissant des abstractions qui cachent tout ce qu’on vous a expliqué précédemment. Curator propose en effet :
- Un système de gestion de leader avec un algorithme de sélection garantissant à la fin un leader unique.
- Un système complet de gestion des verrous : mise en place de verrous partagés, mise en place d’un système de barrières. Les barrières sont une condition bloquante sur un nœud et ses enfants. Tant que la condition n’est pas vérifiée, le nœud reste bloqué.
- Un système de caches sur le contenu d’un nœud.
- Un système de compteur (exactement comme une séquence en Oracle) distribué. C’est particulièrement utile pour savoir qui a la dernière version d’une information.
- La gestion de la communication avec des queues : queue avec id, queue avec priorité sont deux exemples
Par exemple, sur la documentation officielle ( ) on trouve ce fragment de code qui vaut bien mieux qu’on long discours :
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if ( lock.acquire(maxWait, waitUnit) )
{
try
{
// do some work inside of the critical section here
}
finally
{
lock.release();
}
}
Conclusion
Nous avons mis en place, sur une mission précédente, un outil de synchronisation de processus par une queue stockée en base sans se baser sur un framework. Le retour d’expérience est simple : il est indispensable de ne pas réinventer la roue sur des problématiques complexes comme la conception d’un système distribué. Donc, Zookeeper a vraiment sa place dans une architecture. Pour autant, est-ce la solution ultime, celle qui répond forcément à chaque besoin client ? Non, mais en tant que brique logicielle avec un outil complémentaire par dessus, elle prend tout son sens. A ce titre, connaitre ce framework est
une étape nécessaire pour administrer ou concevoir un système distribué. Mais Storm est un bon exemple de l’abstraction qu’on peut attendre au-dessus de Zookeeper.
Et si vous voulez en savoir plus
- Storm et Zookeeper:
- Présentation en français de Zookeeper
- Zookeeper en pratique:
- Paxos, la base de la coordination:
- Le ZAB en détail
- Comprendre les queues en Zookeeper :


Super article! Je viens tout juste d’installer la suite de Confluent (Zookeeper + Kafka + Kafka REST) que je teste actuellement dans ma boite et j’avais un peu de mal à comprendre à quoi pouvait bien servir Zookeeper. Merci pour tes lumières, je vais suivre ton blog de près! 🙂