
Introduction à Spark
Spark est un framework pour traiter de gros volumes de données de manière distribuée. Initialement imaginé dans le laboratoire AMPLab de l’université de Berkeley pour répondre à certains manques des frameworks Map/Reduce, c’est aujourd’hui un projet open-source hébergé par la fondation Apache, supporté par Databricks et les principales distributions Hadoop (Cloudera, Hortonworks, MapR).
Des Streams aux RDDs
Si vous maîtrisez l’API Stream introduite dans Java 8, ou les FluentIterables de Guava, vous ne serez pas déboussolés car Spark reprend les mêmes concepts:
// Java 8
metrics.stream()
.filter(metric -> metric.getName().equals("cpu.user"))
.mapToLong(metric -> metric.getValue())
.summaryStatistics().getAverage();
// Spark
metricRdd
.filter(metric -> metric.getName().equals("cpu.user"))
.mapToDouble(metric -> metric.getValue())
.mean();
On part d’un jeu de données sur lequel on applique en chaîne des opérations. Spark propose dans son DSL plus d’une vingtaine d’opérateurs dont filter, map, flatMap, reduce , count, distinct, collect, forEach comme dans les Streams Java 8 ou join, leftOuterJoin, union ou groupBy comme dans les bases de données relationnelles.
Un RDD, ou Resilient Distributed Dataset, est le concept central du framework Spark. C’est un jeu de données qui se parcourt comme une collection. Il est distribué, car il sera vraisemblablement partitionné (découpé en partitions), et chacune des partitions traitée sur un noeud du cluster. Il est résilient, car il sera peut-être partiellement relu en cas de problème (perte d’un noeud par exemple).
Comme une collection, un RDD peut-être constitué de types simples (Int, String…) ou structurés. Les types structurés (comme l’objet Metric dans l’exemple ci-dessus) seront immuables pour permettre la parallélisation et sérialisables car ils seront amenés à voyager d’un noeud à l’autre.
Pour créer un RDD, on peut partir de:
- Une collection (List, Set), transformée en RDD avec l’opérateur
parallelize - Un fichier local ou distribué (HDFS) dont le format est configurable: texte brut, SequenceFile Hadoop, JSON, ProtoBuf (via Elephant Bird)…
- Une base de données: JDBC, Cassandra, HBase…
- Un autre RDD auquel on aura appliqué une transformation comme
filter,map…
Le chemin inverse, exporter un RDD dans un fichier, dans une base de données ou un collection est aussi possible.
Du localisé au distribué
Lancer Spark en local est très utile pour développer gentiment sur son poste et tester unitairement ses chaînes de traitements. Il suffit de quelques lignes de code pour démarrer Spark:
public class MetricSparkTest {
private JavaSparkContext sparkContext;
@Before
public void setUp() {
SparkConf conf = new SparkConf(true)
.setMaster("local")
.setAppName("Zenika");
this.sparkContext = new JavaSparkContext(conf);
}
@Test
public void testMeanCpuUser() throws Exception {
Double mean = sparkContext.textFile("file://metric.txt")
.map(Metric::parseLine)
.filter(metric -> metric.getName().equals("cpu.user"))
.mapToDouble(metric -> metric.getValue())
.mean();
assertEquals(74.0D, mean, 0.1D);
}
}
Néanmoins, ne perdons pas de vue que l’objectif de Spark est de pouvoir répartir les traitements sur plusieurs machines. Dans ce but, une machine maître écoute les demandes de traitement clientes, découpe chaque traitement et, comme tout bon chef, délègue sa réalisation à des machines esclaves. Ces dernières vont accomplir le travail demandé en parallèle.

Pour passer d’une exécution locale à un cluster, seule la configuration Spark (voir l’objet SparkConf) change, l’emplacement du noeud maître n’est plus local mais spark://...
SparkConf conf = new SparkConf(true)
.setMaster("spark://maitre:7077")
Pour paralléliser un traitement, il faut être capable de le découper. Ce partitionnement des données sera déterminé par la source de données ou bien pourra être imposé par le développeur. Premier exemple, pour HDFS on obtient par défaut une partition par bloc (64Mo):
sparkContext.textFile("hdfs://metric.txt");
Second exemple, sur un RDD de type couple clé/valeur, on peut se servir de la clé (et d’une fonction de hachage) pour forcer le partitionnement:
metricRdd
.mapToPair(metric -> new Tuple2<>(metric.getName(), metric))
.partitionBy(new HashPartitioner(100))
Sur des opérations comme les join, groupBy par exemple, la maîtrise du partitionnement est vital pour limiter le volume de données brassé entre les noeuds et ainsi garantir des performances acceptables.
Caching et lazy-evaluation
Revenons à l’exemple complet:
Double mean = sparkContext.textFile("file://metric.txt") // 0
.map(Metric::parseLine) // 1
.filter(metric -> metric.getName().equals("cpu.user") // 2
.mapToDouble(metric -> metric.getValue()) // 3
.mean() // 4;
Lorsque les opérations 1 à 3 se déclenchent, rien ne se passe immédiatement, ce sont des transformations: elles convertissent un RDD en un autre RDD. En pratique, elles ne font qu’assembler des composants entre eux, chacun d’eux venant envelopper et décorer son ou ses prédécesseurs pour obtenir un nouveau RDD:

Seule la quatrième et dernière étape va réellement déclencher l’exécution de toutes les précédentes, c’est une action. Dans une architecture distribuée, cette action va se traduire par la soumission d’un job à l’ensemble du cluster.
En procédant ainsi, pour effectuer un autre traitement sur le même jeu de données issu de l’étape 1, je serai amené à relire et reparser le fichier source (étapes 0 et 1). Avec les opérations cache et persist, Spark permet de conserver temporairement un résultat de transformation, cela permettra de réutiliser des résultats intermédiaires et d’éviter des recalculs superflus:
JavaRDD<Metric> metricRdd = sparkContext.textFile("file://metric.txt")
.map(Metric::parse)
.cache();
Double mean = metricRdd
.filter(metric -> metric.getName().equals("cpu.user") // 2
.mapToDouble(metric -> metric.getValue())
.mean();
Map<String, Long> metricByHost = metricRdd
.map(metric -> metric.getHost())
.countByValue();
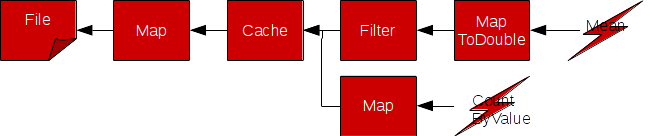
Spark permet ainsi de conserver temporairement un RDD en mémoire (on heap ou off heap avec Tachyon) et/ou sur le disque local. Si le résultat n’a pas pu être conservé (cache miss), il sera recalculé.
Déploiement
 Exécuter des traitements lourds sur un cluster, piloter les noeud esclaves, leur distribuer les tâches équitablement, et arbitrer la quantité de CPU et de mémoire qui sera allouée à chacun des traitements, tel est le rôle d’un gestionnaire de cluster. Spark offre pour l’instant trois solutions pour cela: Spark standalone, YARN et Mesos. Livré avec Spark, Spark Standalone est le moyen le plus simple à mettre en place. Ce gestionnaire de cluster s’appuie sur Akka pour les échanges et sur Zookeeper pour garantir la haute-disponibilité du noeud maître. Ce n’est pas jouet, c’est un réel outil paré pour la production: Il dispose d’une console pour superviser les traitements, d’un mécanisme pour collecter les logs des esclaves…
Exécuter des traitements lourds sur un cluster, piloter les noeud esclaves, leur distribuer les tâches équitablement, et arbitrer la quantité de CPU et de mémoire qui sera allouée à chacun des traitements, tel est le rôle d’un gestionnaire de cluster. Spark offre pour l’instant trois solutions pour cela: Spark standalone, YARN et Mesos. Livré avec Spark, Spark Standalone est le moyen le plus simple à mettre en place. Ce gestionnaire de cluster s’appuie sur Akka pour les échanges et sur Zookeeper pour garantir la haute-disponibilité du noeud maître. Ce n’est pas jouet, c’est un réel outil paré pour la production: Il dispose d’une console pour superviser les traitements, d’un mécanisme pour collecter les logs des esclaves…
Pour lancer les process:
// Spark Master
spark-class org.apache.spark.deploy.master.Master
// Spark Slave (Worker)
spark-class org.apache.spark.deploy.worker.Worker spark://maitre:7077
Autre possibilité, YARN le gestionnaire de cluster Hadoop, Spark peut s’exécuter dessus, et aux côtés de jobs Hadoop. Enfin, plus sophistiqué et plus généraliste, Mesos permet de configurer plus finement l’allocation des ressources (mémoire, CPU) aux différentes applications.
Une fois notre traitement mis au point et notre cluster prêt, il ne reste plus qu’à lancer le traitement. On commence par empaqueter tout le code et les librairies utilisées dans un gros Jar (un fatjar/uberjar). Puis on utilise la commande spark-submit pour soumettre le traitement au cluster:
spark-submit --master spark://maitre:7077 \
--class com.zenika.metric.spark.Main \
--executor-memory 1G \
--total-executor-cores 8 \
metric-spark.jar
Multi-langage
Les exemples présentés jusqu’ici étaient écrits en Java pour être accessibles au plus grand nombre. Cependant Spark est écrit en Scala et peut être indifféremment utilisé en Java, en Scala et en Python:
- Scala: certaines fonctionnalités du langage comme les tuples, l’inférence de type, les case classes, les conversions implicites, rendent l’utilisation de Spark fluide. De plus, le Spark Shell, qui s’appuie sur le REPL Scala, permet l’écriture et l’exécution de traitements en direct.
- Python: en attendant SparkR, c’est un des langages préférés des data scientists, on dispose, comme en Scala, d’un REPL (PySpark), de tuples, d’un typage flexible… Mais certaines fonctionnalités purement Java ou Hadoop ne sont pas accessibles.
- Java: la version 8 est presque obligatoire pour tirer parti des expressions lambda. La couche d’adaptation Java/Scala et le typage explicite nécessaire rend l’utilisation un peu plus lourde, mais reste acceptable.
La plupart des exemples de la documentation sont décrits dans les 3 langages.
Modules additionnels
Au dessus de Spark, des librairies additionnelles apportent des fonctionnalités supplémentaires:
- Spark SQL: permet d’exprimer les traitements (map, filter, reduce) sous la forme d’un langage inspiré de SQL
- MLLib: est une bibliothèque d’algorithmes de Machine Learning pour classifier, regrouper les données (k-Means), faire des recommandations…
- Spark Stream: là où Spark excelle dans les traitements en masse de gros volumes de données, Spark Stream applique des recettes semblables pour des traitements au fil de l’eau
- GraphX: apporte les outils pour explorer les graphes
Dans cette courte introduction à Spark, nous avons parcouru les principaux concepts de ce framework de traitement distribué: RDD, transformations, actions, partitionnement… ainsi que quelques unes de ces qualités: développement simples et maintenables, possibilités d’optimisation… Je détaillerai un peu plus Spark SQL et Spark Stream dans un prochain épisode.
A suivre…



Bonjour !
Merci beaucoup pour cet article très bien fourni et intéressant.
Je souhaite déployer des workers sur d’autres machines connectées à mon réseau. (je connais donc leur IP). Comment faire pour utiliser les ressources de ces machines en déployant des workers dessus, tout en restant attaché sur le même master ?
Merci d’avance