
Zenika à la conférence Devoxx-fr 2012 !
La semaine dernière se tenait la conférence Devoxx-fr 2012, la première adaptation française du fameux Devoxx belge, point de ralliement incontournable de tous les développeurs Java européens.
Grâce à Zenika, j’ai pu assister à l’intégralité de la conférence, et présenter moi-même deux sessions, dont je vous reparlerai dans un prochain billet. Trois jours exténuants mais passionnants, dont je vous propose une rétrospective.
Organisation
 Pour sa première instance hexagonale, Devoxx-fr a investi le centre de conférences de l’hôtel Mariott, dont la moquette aux motifs psychédéliques a déjà acquis une certaine renommée.
Pour sa première instance hexagonale, Devoxx-fr a investi le centre de conférences de l’hôtel Mariott, dont la moquette aux motifs psychédéliques a déjà acquis une certaine renommée.
A part cet aspect esthétique contestable, l’organisation était parfaite. L’hôtel, situé en plein Paris, était facilement accessible, et proposait un espace vaste et lumineux. Le buffet de midi était très correct et il y avait même du café à profusion.
L’agenda était quant à lui bien indiqué devant les salles, et a été scrupuleusement respecté grâce aux organisateurs. Une application mobile a même été développée pour l’occasion, reprenant les informations du site.
C’est donc dans ces excellentes conditions que j’ai pu assister aux conférences.
Le choix fut difficile : avec 3 salles en haut et 4 en bas, c’étaient autant d’événements intéressants qui pouvaient avoir lieu en parallèle. Heureusement, tout a été filmé et sera bientôt disponible sur la plateforme Parleys.
Sessions
Introduction à Cassandra
Par Nicolas Romanetti
![]() La première matinée était consacrée à une session « university » présentant Apache Cassandra.
La première matinée était consacrée à une session « university » présentant Apache Cassandra.
Cassandra est une base de données NoSQL développée à l’origine par Facebook, puis donnée à la fondation Apache. Orientée colonnes, on pourrait la comparer sa structure interne à une « Map de Maps » : chaque ligne stocke un ensemble de données potentiellement différent.
Certaines fonctionnalités des bases de données classiques ont été volontairement laissées de côté (les jointures notamment) afin de faciliter la montée en charge. La clusterisation symétrique auto-balancée et la gestion fine des niveaux de réplication garantissent la sécurité et la haute disponibilité des données (« tuneable consistency« ).
Cassandra propose plusieurs modes de requêtage et d’interaction, dont le Cassandra Query Language (CQL) qui ne devrait pas trop dépayser les développeurs SQL « classiques ». Le protocole Thrift, très compact, est utilisé pour les communications réseau.
Je ne connaissais Cassandra que de nom. C’était une occasion idéale pour découvrir le produit, et je dois dire qu’il m’a paru très intéressant : une brique de plus dans ma besace d’architecte !
The Productive Programmer
Par Neal Ford
L’après-midi fut l’objet d’un arbitrage difficile, entre les sessions « Productive programmer » de Neal Ford, et le « Guide de survie en théorie des langages » d’Alexandre Bertails. Pile ou face, que choisir ?
Et puis tout de même, Neal Ford, ThoughtWorks… ça ne se refuse pas.
La présentation de Neal était organisée en 2 parties : les aspects physiques/techniques de la productivité d’un développeur, puis les aspects liés à la programmation en tant que tel.
Du côté physique/technique, on retrouvait les conseils habituels, qui lui paraissaient évidents (mais pas tant que ça de ce côté de l’Atlantique apparemment) :
- Utiliser le clavier plutôt que la souris (apprenez les raccourcis de votre IDE et de votre OS !),
- Disposer de plusieurs écrans de grande taille, d’un grand bureau et d’une bonne chaise ergonomique,
- S’isoler des perturbations environnementales (son, mouvement, téléphone…)
- Automatiser le travail : templates de code, scripts, enregistreurs de macros…
Du côté programmation :
- Découper le code en méthodes cohérentes et si possible « pures » (au sens de la programmation fonctionnelle) : principes SLAP, DRY
- Pratiquer le Test-Driven Design/Development (TDD) : principe YAGNI
- Garantir la qualité du code avec l’intégration continue et les outils d’analyse de code
- Ne pas hésiter à questionner et faire évoluer les pratiques établies en entreprise.
- Apprendre un langage en profondeur (certifications), et plusieurs langages de types différents (objet, prototype, fonctionnel…) pour la culture générale.
Neal Ford est toutefois un excellent orateur et les trois heures sont passées rapidement. Il nous a même dévoilé le secret de l’algorithme de gestion des fantômes de Pacman ! Mais la présentation en elle-même n’avait rien de bien révolutionnaire. Une partie du message est sans doute davantage destinée à des chefs de projets ou DSI, qui doivent équiper et organiser leurs équipes.
En tout cas, les conditions de travail chez ThoughtWorks ont fait rêver toute la salle… La question est : sont-elles une cause ou une conséquence de l’excellence de cette société ?
La programmation GPGPU facile avec JavaCL et ScalaCL
Par Olivier Chafik
![]() Après la session très théorique de Neal Ford, retour au code pur et dur avec la session OpenCL d’Olivier Chafik.
Après la session très théorique de Neal Ford, retour au code pur et dur avec la session OpenCL d’Olivier Chafik.
Aujourd’hui, les puces équipant les cartes graphiques sont nettement plus puissantes que les processeurs pour l’exécution des calculs mathématiques, en particulier vectoriels et matriciels. Le gain espéré est d’environ 5x.
Les vendeurs de ces puces appelées GPGPU (General-Purpose Graphics Processing Units) ont standardisé un langage très bas niveau, à la syntaxe proche du C, permettant leur programmation : OpenCL (Open Computing Language). L’objectif de la session était de présenter les bindings existant pour Java et Scala.
Du côté Java, il existe un plugin Maven qui permet de générer des classes wrapper facilitant l’exécution des routines OpenCL et la récupération des résultats ; mais il faut tout de même écrire le code OpenCL manuellement.
Du côté Scala, un plugin pour le compilateur permet d’écrire du code Scala standard, et de le traduire à la volée en code OpenCL. Cela fonctionne particulièrement bien pour les opérations parallélisables sur les collections (map, filter, etc.).
Évidemment, tout n’est pas rose, et certaines limitations sont à prendre en compte : compatibilité inter-vendeurs, lenteur des instructions de débranchement (« if / else« ), coût du transfert des données de la mémoire centrale à la mémoire graphique…
Une session très intéressante donc, et qui sortait des sentiers battus des frameworks d’entreprise.
Android Annotations
Par Pierre-Yves Ricau et Alexandre Thomas
![]() Cette session-ci me tenait particulièrement à cœur.
Cette session-ci me tenait particulièrement à cœur.
AndroidAnnotations est un projet opensource qui vise à simplifier le développement des applications Android. Il se base sur les AnnotationProcessors, technique que Pierre-Yves a découverte lors de ma conférence au Paris JUG. Je ne pouvais donc que venir l’encourager !
La session a consisté principalement en un refactoring live d’une application existante. A l’aide d’une poignée d’annotations, Pierre-Yves a simplifié la récupération des composants, la gestion de leurs handlers, le lancement de traitements asynchrones… Le code final ne faisait plus que le tiers du code initial !
Un beau projet donc, qui mériterait d’être inclus dans le SDK Android.
JDK 8 demo: lambdas in Action
Par Guillaume Tardif
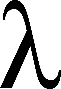 Java 8 va arriver vite, très vite. Et avec lui les changements les plus radicaux depuis Java 5 ! Il est donc important de s’y préparer.
Java 8 va arriver vite, très vite. Et avec lui les changements les plus radicaux depuis Java 5 ! Il est donc important de s’y préparer.
A l’aide du JDK8 Lambda Preview, Guillaume a fait démonstration de ses fonctionnalités les plus marquantes : les closures et les defender methods.
Les closures sont (pour simplifier) des blocs de code nommés, pouvant notamment être passés en paramètre d’autres méthodes. On reconnaît ici le concept de higher-order methods cher aux langages fonctionnels (Haskell, Lisp…).
Leur arrivée dans le langage est une révolution, qui va bouleverser notre façon de développer. Dans un premier temps, les changements dans l’API Collection constitueront la partie la plus visible de l’iceberg. Mais les frameworks d’entreprise (Spring, Java EE, Hibernate…) seront rapidement mis à jour, et il n’y aura plus de retour en arrière possible. Préparez-vous !
Les defender methods offrent quant à elles la possibilité de définir du code dans les interfaces. Ca ressemble presque à un mixin, mais en pratique c’est surtout le retour du fameux problème de « l’héritage en diamant » que Java avait si soigneusement cherché à éviter depuis sa conception.
Le but officiel est de pouvoir, par exemple, définir implémentation de la méthode « sort() » sur l’interface List, afin que toutes les listes soient triables en appelant « maListe.sort()« .
Personnellement, je ne vois pas réellement de gain par rapport à la notation actuelle « Collections.sort(maListe) » ; en revanche, l’héritage en diamant ouvre la voie à toute une nouvelle catégorie d’erreurs de conception et de problèmes de compilation (que faire si deux interfaces fournissent des implémentations différentes d’une même méthode ?).
Autant j’attends les closures avec impatience, autant certaines autres fonctionnalités me paraissent davantage tenir du « sucre syntaxique » dangereux, introduites surtout pour complaire aux utilisateurs de langages « alternatifs », que d’une véritable fonctionnalité indispensable.
« Wait & see« , donc.
Manipulation de bytecode
Par Julien Ponge et Fredéric Le Mouel
Deuxième jour.
Après une matinée de keynotes animées par l’équipe du Paris Jug puis par le duo de choc Ben Evans et Martijn Verburg, on attaque les conférences.
Et on attaque fort, avec la présentation de différentes librairies de manipulation de bytecode.
Tout d’abord, Julien a montré comment coder un « Hello World » from scratch, directement en bytecode, à l’aide de la librairie ASM. D’accord, ce n’est sûrement pas le use-case le plus courant, mais il faut savoir que de nombreux frameworks d’entreprise s’en servent pour générer ou modifier des classes à la volée.
Ensuite, AspectJ a été utilisé pour modifier du code existant : ajout d’un cache de résultats sur la méthode calculant l’incontournable suite de Fibonacci, puis ajout d’une interface Comparable (et de l’implémentation de compareTo() associée) sur une classe.
Après ça, le projet Byteman a été présenté. Développé par JBoss, il se présente sous la forme d’un Agent Java permettant d’injecter du code à chaud (en production !) dans une application existante.
Les use-cases sont nombreux, mais l’un des plus intéressants est la possibilité de simuler des conditions rares dans les tests unitaires (par exemple, simuler l’impossibilité d’écrire un fichier sur un disque plein). Un projet à suivre, donc.
Et pour finir, la présentation d’un projet en cours de développement par Julien, et qui gagne l’oscar du nom le plus rigolo de toute la conférence : JooFlux.
JooFlux modifie le bytecode pour remplacer les appels « normaux » de méthodes (invokestatic, invokevirtual…) par des appels de type invokedynamic, afin de pouvoir changer à chaud la destination des appels, tout en restant « JIT-friendly ».
Cette séance était donc intéressante pour la diversité des outils présentés, et a sûrement donné envie aux spectateurs de mettre les mains dans le cambouis. Qui sait sur quoi cela débouchera ?
InvokeDynamic
Par Rémi Forax
Après la manipulation de bytecode vue à la session précédente, Rémi Forax nous a entraînés encore une couche plus bas : directement au niveau de l’assembleur généré par le JIT. Vous avez dit « hardcore » ?
Avertissement : le compte-rendu ci-dessous est probablement imprécis, incomplet, voire complètement faux. Le sujet était très pointu et pas évident à comprendre… Je vous recommande donc de regarder la présentation de Rémi sur Parleys, et de vous faire votre propre idée.
Rémi explique que le principal travail de la JVM est de malaxer, préparer, organiser le code de manière à le rendre le plus digeste possible pour le CPU – en particulier pour limiter les sauts (ex: « if / else« ) dans le code afin de ne pas vider les « cache lines« .
Par exemple, si l’une des branches d’un « »if/else » » est empruntée dans 99% des cas, elle sera inlinée et un simple test vérifiera si l’on n’est pas dans l’autre cas. Les appels de méthodes également : si une implémentation particulière d’une interface est utilisée dans 99% des cas, la JVM remplacera l’appel polymorphique par un appel direct, et insèrera un simple test sur le type de la classe pour gérer les autres cas.
Rémi a ensuite présenté l’instruction invokedynamic. Comme les autres instructions de la famille invokeXXX, elle permet d’effectuer un appel de méthode – la différence étant que cet appel sera résolu de manière complètement dynamique au runtime, et optimisé par le JIT comme vu plus haut.
Les langages dynamiques (JRuby, Groovy) sont les premiers clients de cette fonctionnalité apparue avec Java 7, qui leur permettra d’optimiser leurs appels de méthodes et d’obtenir de bien meilleures performances générales.
En conclusion, cette séance était très intéressante, mais également très difficile à suivre. Rémi est enseignant-chercheur et membre de des Expert Groups relatifs à invokedynamic et aux « closures », et maîtrise parfaitement le sujet. Mais pour le commun des mortels, c’était un peu de la science-fiction…
A revoir au calme et avec une aspirine.
GWT à l’épreuve du feu
Par Sami Jaber
![]() On remonte de quelques couches, pour arriver à Google Web Toolkit (GWT).
On remonte de quelques couches, pour arriver à Google Web Toolkit (GWT).
Sami Jaber, connu pour ses travaux sur ce framework, a présenté un use-case un peu extrême, développé pour un client dans le domaine de l’audio/vidéo-conférence.
Les principaux points forts de l’application étaient l’intégration temps-réel avec les API téléphoniques pour pouvoir composer un numéro ou répondre automatiquement à un appel entrant, et la répartition des appels entre les centres de support internationaux.
L’application devait également s’interfacer avec le système existant de type .Net.
GWT a donc prouvé sa capacité à amener la réactivité d’un client de type desktop dans l’univers du web.
Google App Engine
Par Didier Girard et Ludovic Champenois
 Toujours dans l’univers Google, Didier Girard a présenté la plateforme Google App Engine.
Toujours dans l’univers Google, Didier Girard a présenté la plateforme Google App Engine.
GAE n’est pas un simple serveur d’applications – c’est en réalité tout un écosystème pour le développement d’applications dans le cloud :
- Des instances de serveurs pour le front-end (web) et le back-end (calculs, batches…), activées automatiquement en fonction de la charge
- Du stockage de type SQL (MySQL), NoSQL (DataStore / BigTable), et de cache (MemCached)
- Des services réseau de type Mail, XMPP, URLFetch
- Une authentification centralisée
- Des services divers pour la manipulation d’image, la conversion de documents…
Didier insiste sur le fait que cette plateforme, en plus d’être très complète et hautement scalable, est également très bon marché.
Son application « A Bon Entendeur », qui accepte plus de 6000 utilisateurs simultanés (60 requêtes/seconde) en moyenne, ne lui coûte que quelques euros par jour. Le site du président Obama, qui a reçu jusqu’à 700 requêtes par seconde lors de son élection, a également tenu la charge sans souci. La plateforme GAE est donc particulièrement adaptée aux communications événementielles.
J’avais déjà assisté aux précédentes conférences de Didier, et celle-ci n’avait rien de bien neuf. Mais Dider est enthousiaste et bon orateur, et il a sûrement donné envie à l’audience de tester le produit.
Mais aussi…
Devoxx-fr, c’était 3 jours de conférences passionnantes, mais c’était également l’occasion de rencontrer du monde. Beaucoup de monde.
Et même beaucoup, beaucoup de monde ! 1250 participants, plus les sponsors et les organisateurs : une armée de bipèdes caféinés qui ont réussi à circuler sans trop de heurts entre les stands et les salles de conférence, grâce à une organisation efficace. Bravo !
Du côté des sponsors, les stands proposaient des animations variées comme des combats de robots Lego Mindstorm, le pilotage de quadricoptères radioguidés, et divers concours et tirages au sort. Ainsi que les incontournables goodies publicitaires, évidemment.
Conclusion
Pour sa première instance, Devoxx-fr était une franche réussite.
Des présentations intéressantes, des speakers renommés, une organisation sans faille et une moquette hypnotique, tous les ingrédients étaient réunis pour en faire the place to be en 2012.
Vivement l’année prochaine !


