
Le conte de Litil – Chapitre 2, Le dépeceur du texte, aka Lexer
Dans ce deuxième post du conte de Litil, je vais parler de la phase de lexing. C’est généralement la première étape dans la construction d’un compilateur (ou évaluateur) d’un langage donné. Cette phase sert à transformer le texte du code source (séquence de caractères) vers une séquence de tokens, qui seront consommés par le parseur à l’étape suivante.
Les règles suivant lesquelles le texte est découpé en tokens varient d’un langage à un autre, mais en général (avec les langages conventionnels de la famille Algol par exemple), on peut définir les familles de tokens suivants:
symboles: les opérateurs (+, -, *, /, etc.), les signes de ponctuation (,, ;, (, [, etc.).
les littéraux: nombres (42, 3.14, etc.), chaînes de caractères ("kthxbye"), booléens (true, false).
les mots clés: if, while, etc.
les identifiants: cela dépend du langage, mais généralement un identifiant commence par une lettre ou un tiret-bas (_), puis optionnellement une séquence de lettres, chiffres et quelques autres symboles.
On peut donc voir un token comme un couple type (symbole, mot clé, littéral, etc.) et valeur (le contenu textuel de ce token). Optionnellement, on peut enrichir un token pour contenir aussi le numéro de la ligne et de la colonne où il apparait dans le texte source, ce qui peut s’avérer utile pour signaler l’emplacement d’une erreur.
Enfin, le lexer se charge de cacher ou ignorer le contenu inutile dans le fichier source, comme les blancs, retours à la ligne et autres.
Gestion des blancs
Dans le langage que nous allons implémenter, et à l’encontre de la majorité des autres langages, les blancs sont importants car il servent à démarquer le début et la fin des blocs comme dans Python (et Haskell) par exemple. Le début d’un bloc est signalé par une augmentation du niveau de l’indentation tandis que sa fin est marquée par une dé-indentation.
Exemple:
if n > 0 then let x = 10 / n print "Ohai" else throw Error
L’équivalent Java serait:
if (n > 0) {
int x = 10 / n;
System.out.print("Ohai");
} else {
throw new Exception();
}
Bien que les corps des branches then et else du code java sont bien indentés, cette indentation est optionnelle et est carrément ignorée par le lexer. Ce sont les accolades ouvrantes et fermantes qui démarquent le début et la fin d’un bloc. On aurait pu obtenir le même résultat avec:
if (n > 0) {
int x = 10 / n;
System.out.print("Ohai");
} else {
throw new Exception();
}
ou encore:
if (n > 0) {int x = 10 / n;System.out.print("Ohai");} else {throw new Exception();}
La lisibilité du code en souffre, mais cela ne change rien du point de vue du compilateur. Ce n’est pas le cas avec Litil, où comme dit plus haut, l’indentation du code n’est pas optionnelle car elle sert à définir sa structure. De plus, là où dans Java on utilisait le ; pour séparer les instructions d’un même bloc, Litil utilise plutôt les retours à la ligne. Les ; ne sont pas optionnels, ils ne sont pas reconnues. Mon but était de s’inspirer des langages comme Haskell et Python pour créer une syntaxe épurée avec un minimum de bruit et de décorum autour du code utile. Je reviendrai là dessus dans le(s) post(s) à venir quand je vais détailler la syntaxe de Litil, mais pour vous donner quelques exemples:
Pas d’accolades pour délimiter les blocs
Pas de ; pour séparer les instructions
Pas de parenthèse pour les arguments d’une fonction: sin 5
Pas de parenthèse pour les conditions des if
etc.
Donc, pour résumer, le lexer que nous allons développer ne va pas complètement ignorer les blancs. Plus précisément, le lexer devra produire des tokens pour signaler les retours à la ligne (pour indiquer la fin d’une instruction) et les espaces (ou leur absence) en début de lignes (pour indiquer le début ou la fin d’un bloc).
Implémentation
Pour commencer, voici la définition d’un Token:
public class Token {
public enum Type {
NEWLINE, INDENT, DEINDENT, NAME, NUM, STRING, CHAR, SYM, BOOL, KEYWORD, EOF
}
public final Type type;
public final String text;
public final int row, col;
public Token(Type type, String text, int row, int col) {
this.type = type;
this.text = text;
this.row = row;
this.col = col;
}
}
Un token est composé de:
type: le type du token:
NEWLINE: pour indiquer un retour à la ligne
INDENT: pour indiquer que le niveau d’indentation a augmenté par rapport à la ligne précédente, et donc qu’on entre dans un nouveau bloc
DEINDENT: pour indiquer que le niveau d’indentation a diminué par rapport à a ligne précédente, et donc qu’on sort d’un bloc
NAME: une clé pour indiquer qu’il s’agit d’un identifiant
NUM, STRING, CHAR, BOOL: une clé pour indiquer qu’il s’agit d’un littéral
KEYWORD: une clé pour indiquer qu’il s’agit d’un mot clé
EOF: produit quand on a atteint la fin du texte source
text: une chaîne qui contient le texte correspondant à ce token
row et col: indique la position du token dans le texte source
Voici maintenant l’interface qui décrit le lexer:
public interface Lexer {
Token pop() throws LexingException;
String getCurrentLine();
}
Cette interface définit les 2 méthodes suivantes:
pop: retourne le token suivant
getCurrentLine: retourne la ligne courante dans le texte source
Notez l’absence d’une méthode qui indique la présence ou pas d’un token suivant. En effet, quand le lexer atteint la fin du fichier, il se place en un mode où tous les appels à pop retournent un token de type EOF. J’ai donc estimé inutile d’alourdir l’interface pour ajouter une méthode à la hasNext d’un itérateur par exemple.
Notez aussi que si j’ai défini une interface pour le lexer, c’est parce qu’il y aurait plusieurs implémentations que nous allons voir par la suite.
Comment ça fonctionne
Voici une présentation rapide du fonctionnement de l’implémentation de base du lexer (Code source de BaseLexer.java sur Github) pour ceux qui voudront suivre avec le code sous les yeux:
Le constructeur du lexer prend en paramètre un java.io.Reader qui pointe vers le texte source
Le lexer définit un champ currentLine qui contient la ligne courante et 2 autres champs row et col pour la position
Quand pop est appelée, on teste si la ligne courante est renseignée ou pas. Si elle ne l’est pas, on essaie de lire une ligne complète du Reader. Si la méthode retourne null, c’est que la fin du texte source est atteinte, et dans ce cas le lexer se place en un mode où il retourne toujours un token de type EOF.
Sinon, et après avoir traité les indentations au début de la ligne (je vais revenir là dessus plus tard), le lexer examine la première lettre de la ligne pour choisir la branche à suivre
Si c’est une lettre, alors il continue à consommer la ligne un caractère à la fois jusqu’à ce qu’il trouve autre chose qu’une lettre ou un chiffre, en accumulant les caractères lus dans une chaîne
Si cette chaîne est égale à true ou false, il retourne un token de type BOOL.
Si cette chaîne figure dans la liste des mots clés, il retourne un token de type KEYWORD
Sinon, c’est que c’est un identifiant. Il retourne alors un token de type NAME
Si le premier caractère est un chiffre, le lexer continue de consommer les caractères tant qu’il trouve des chiffres, puis il retourne un token de type NUM
Si c’est plutôt " ou ', le lexer lit la chaîne ou le caractère et retourne un token de type STRING ou CHAR. Ce n’est pas très compliqué comme traitement, si ce n’est pour gérer les échappements (" ou n par exemple)
Le lexer tente ensuite de lire un symbole parmi la liste des symboles qu’il reconnait. Je vais revenir sur cette partie plus tard, mais l’idée est d’utiliser un automate en essayant de matcher le symbole le plus long (par exemple, matcher un seul token avec la valeur -> plutôt que 2 tokens - et >)
Enfin, si on a atteint la fin de la ligne, on remet currentLine à null. De cette manière, le prochain appel à pop va passer à la ligne suivante. Sinon, on lance une erreur car on est face à une entrée non reconnue
Gestion des blancs
A lecture d’une nouvelle ligne, et avant d’exécuter l’algorithme décrit dans la section précédente, le lexer consomme les espaces en début de ligne en calculant leur nombre, ce qui définit le niveau d’indentation de la ligne. Il compare ensuite cette valeur au niveau d’indentation de la ligne précédente (qu’il maintient dans un champ initialisé à 0):
Si les 2 valeurs sont égales, il retourne un token de type NEWLINE
Si le niveau d’indentation de la ligne courante est supérieur à celui de la ligne précédente, il retourne un token de type INDENT mais il se met aussi dans un mode où le prochain appel à pop retourne NEWLINE. Dans une première version du lexer de Litil, je générais uniquement INDENT ou DEINDENT quand le niveau d’indentation changeait, NEWLINE sinon. Mais cela posait plein de problèmes dans la phase suivante (le parseur) pour délimiter correctement les blocs, jusqu’à ce que je tombe sur cette réponse sur Stackoverflow. En suivant la méthode décrite dans cette réponse, j’ai fini avec une implémentation beaucoup plus simple et surtout solide du parseur. Je reviendrai là-dessus dans le post consacré
au parsing.
Sinon, il retourne un token de type DEINDENT et se met en un mode pour retourner NEWLINE à l’appel suivant
Un exemple pour clarifier un peu les choses. Etant donné ce texte en entrée:
a b c d
Le lexer est censé générer les tokens suivants:
NEWLINE
NAME(a)
INDENT: le niveau d’indentation a augmenté à la 2ième ligne
NEWLINE: toujours produit pour une nouvelle ligne
NAME(b)
NEWLINE: le niveau d’indentation n’a pas changé entre les 2ième et 3ième lignes
NAME(c)
DEINDENT: le niveau d’indentation a diminué
NEWLINE
NAME(d)
EOF: fin de l’entrée
Seulement, l’algorithme décrit jusqu’ici n’est pas suffisant pour que le parseur arrive à gérer proprement l’indentation. En effet, avec l’exemple suivant:
a b
Le lexer ne va pas produire un token de type DEINDENT après le NAME(b) mais plutôt un EOF car il n’y a pas de nouvelle ligne après le b. On pourrait imaginer une solution où le parseur utilise EOF en plus de DEINDENT pour détecter la fin d’un bloc, mais ce n’est pas suffisant. En effet, avec l’exemple suivant:
a
b
c
d
L’implémentation décrite ici va générer un seul token DEINDENTaprès NAME(c) alors que cette position dans le source marque la fin de 2 blocs et non pas un seul.
Pour gérer ce type de situation, et ne voulant pas complexifier encore le code du lexer de base, j’ai décidé de gérer ça dans une autre implémentation de l’interface Lexer, StructuredLexer. Cette dernière implémente le pattern décorateur en délégant à BaseLexer pour générer les tokens du texte source, mais en l’enrichissant avec les traitements suivants:
On maintient le niveau courant d’indentation dans un champ. Le niveau d’indentation est calculé en divisant le nombre d’espaces en début d’une ligne par une taille d’unité d’indentation, fixée à 2 espaces.
Dans pop, si le lexer de base retourne un INDENT:
- Vérifier que le nombre d’espaces est un multiple de l’unité. Si ce n’est pas le cas, retourner une erreur
- S’assurer aussi que le niveau d’indentation n’augmente qu’avec des pas de 1
- Mettre à jour le champ niveau d’indentation
Toujours dans pop, et quand le lexer de base retourne un DEINDENT:
Idem que pour INDENT, s’assurer que le nombre de blancs est un multiple de l’unité d’indentation
Si le niveau d’indentation a diminué de plus d’une unité (comme dans l’exemple précédent), générer autant de tokens DEINDENT virtuels que nécessaires, tout en mettant à jour le champ niveau d’indentation
Si dans pop le lexer de base retourne EOF, produire des DEINDENT virtuels jusqu’à ce que le niveau d’indentation atteigne 0, puis retourner EOF
Ainsi, avec l’exemple suivant:
a
b
c
d
Le lexer structuré génère 1 DEINDENT virtuel, en plus du DEINDENT généré par le lexer de base entre c et d. Comme ça, le parseur au dessus pourra détecter la fin de 2 blocs et détecter correctement que d a le même niveau que a.
Enfin, le code source qui implémente cet algorithme est disponible dans le repo Github de Litil pour les intéressés.
Gestion des commentaires
Dans Litil, les commentaires sont préfixés par -- (double -) et s’étendent sur une seule ligne uniquement. J’ai (arbitrairement) choisi de les gérer au niveau du lexer en les ignorant complètement. Mais j’aurais aussi pu produire des tokens de type COMMENT et les ignorer (ou pas) dans le parseur.
Les commentaires sont gérés à 2 endroits dans le lexer:
Dans le code qui lit une ligne du texte source. Si elle commence par --, on ignore la ligne entière et on passe à la ligne suivante (pour gérer les commentaires en début d’une ligne)
Dans le code qui gère les symboles. Si le symbole matché correspond à --, on passe à la ligne suivante (pour gérer les commentaires à la fin d’une ligne)
Exemples:
-- compute max x y … NOT ! let max x y = x
let max x y = x -- It is a well known fact that x always wins !
Gestion des symboles
Avec la gestion des indentations, c’est la partie la plus intéressante (amha) dans le code du lexer.
Avant de rentrer dans les détails d’implémentation, je vais d’abord parler un peu d’automates finis, qui sont une notion centrale dans la théorie des langages et la compilation.
Un automate fini est un ensemble d’états et de transitions. On peut le voir comme un système de classification: étant donnée une séquence en entrée, il consomme ses éléments un à un en suivant les transitions adaptés (et donc en passant d’un état à un autre) jusqu’à ce qu’il ait consommé toute l’entrée ou encore qu’il arrive dans un état sans aucune transition possible. Quelques états peuvent être marqués comme terminaux ou finals, une façon de dire que ça représente un succès. Donc étant donnée un automate et une entrée, si le traitement s’arrête dans un état terminal, on peut dire qu’on a prouvé une propriété donnée sur l’entrée. Cette propriété va dépendre de l’automate.
Ok, j’explique comme un pied. Un exemple concrêt:

L’automate présenté dans la figure précédente se compose de:
Un état initial (conventionnellement appelé S0). C’est l’unique point d’entrée de l’automate
3 autres états A, B et C. Notez le double contour de ces états. Ca sert à indiquer que ce sont des états terminaux ou d’acceptation
Des transitions entre ces états qui sont annotées par des caractères
Maintenant, appliquons cet automate à la séquence de caractères ->a. Comme dit plus haut, on se positionne initialement au point d’entrée S0. On examine le premier caractère de la séquence d’entrée (->a) et on cherche une transition qui part de cet état et qui est étiquetée avec ce caractère. Ca tombe bien, le premier caractère - correspond bien à une transition entre S0 et A. On suit donc cette trans
ition pour arriver à l’état A et on passe au caractère suivant (>). L’état A est terminal. On pourrait donc interrompre le traitement et dire et qu’on a réussi à matcher le caractère -. Cependant, dans Litil et presque tous les autres langages, le lexer essai plutôt de matcher la séquence la plus longue. L’alternative est qu’il ne faut jamais avoir plusieurs opérateurs qui commencent par le même caractère, ce qui serait trop contraignant.
On continue donc le traitement. A dispose bien d’une transition étiquetée avec >. On suit donc cette transition et on arrive à l’état C qui est aussi terminal. Mais par la même logique, on n’abandonne pas tout de suite et on tente de voir s’il est possible de matcher une séquence plus longue. Ce n’est pas le cas ici car l’état A n’a aucune transition étiquetée avec le caractère a. Le traitement s’arrête donc ici, et comme c’est un état terminal, on retourne un succès avec la chaîne matchée qui ici est ->.
Notez que l’algorithme que je viens de décrire (et qui est utilisé par l’implémentation actuelle du lexer de Litil) est plutôt simpliste et incomplet par rapport à l’état de l’art car il ne gère pas le backtracking. Par exemple, cet algorithme échoue avec l’automate suivante (censé reconnaitre les symboles - et -->) avec la chaîne --a comme entrée alors qu’il devrait réussir à retourner deux fois le symbole - (le pourquoi est laissé comme exercice au lecteur):

Dans sa version actuelle, les symboles reconnus par Litil sont: ->, ., +, -, *, /, (, ), =, %, <, >, <=, >=, :, ,, [, ], |, _, =>, @@, —, ::, { et }@@.
Maintenant, juste pour la science, voici l’automate fini correspondant à ces symboles:
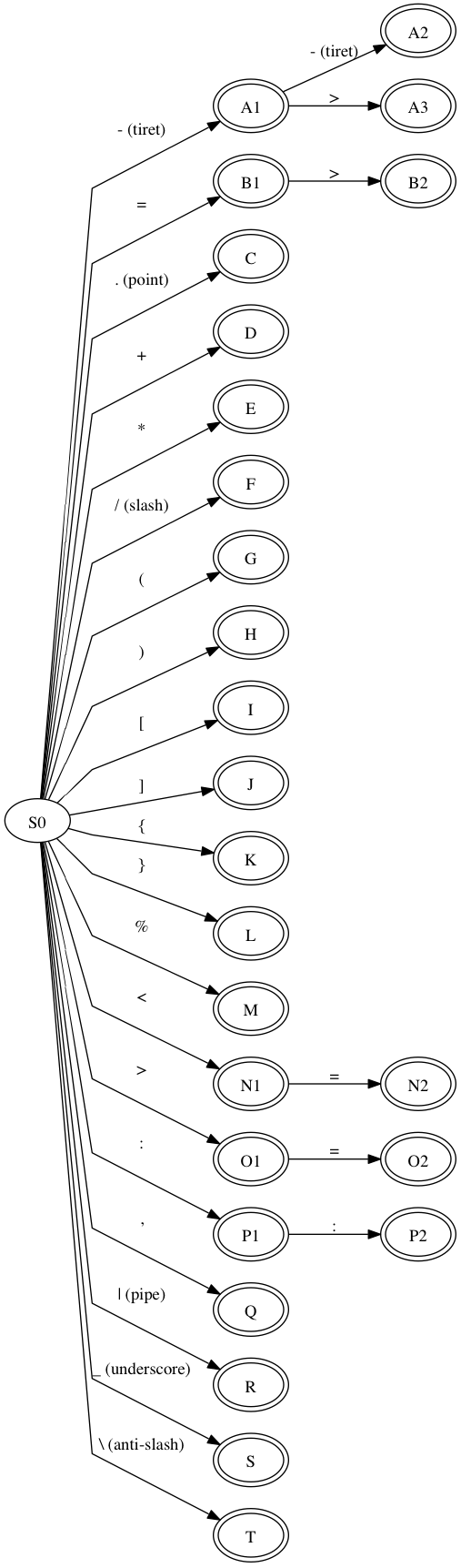
L’implémentation de cet automate dans Litil est dynamique, dans la mesure où l’automate est construit au runtime à partir d’une liste des symboles à reconnaitre. Aussi, cette implémentation ne gère pas le backtracking, qui est inutile pour le moment car, et à moins que je ne dise de bêtises, le problème décrit plus haut n’arrive que si on a des symboles à 3 caractères (et qui ont le même préfixe qu’un symbole à un caractère), ce qui n’est pas le cas dans Litil (ce n’est pas Scala tout de même. Enfin, pas encore). Par contre, l’implémentation tient en 50 lignes de code Java, et si on ignore le décorum de Java (les imports, les getters, le toString, le constructeur, etc.), l’essence de l’algorithme tient juste dans une douzaine de lignes. Voici son code source sur Github pour les intéressés.
Lookahead
Une fonctionnalité utile à avoir dans le lexer est le lookahead, i.e. la possibilité de voir les tokens suivants sans pour autant les consommer (comme c’est le cas avec pop). On va revenir la dessus dans le(s) post(s) à propos du parseur.
Tout comme StructuredLexer, j’ai décidé d’implémenter cette fonctionnalité dans un décorateur autour d’un lexer concrêt, pour ne pas complexifier le code de ce dernier. Il s’agit de la classe LookaheadLexerWrapper (dont voici le code source). L’implémentation derrière est plutôt simple. En effet, l’astuce est juste de maintenir une liste de tokens (en plus du lexer concrêt). Quand la méthode lookahead est appelé (avec un paramètre qui indique le niveau du lookahead: 1 pour le token suivant, etc.), on récupère autant de tokens que nécessaire du lexer et on les stocke dans cette liste. Quand pop est appelée, et avant de déléger au lexer concrêt, on vérifie si la liste de tokens n’est pas vide. Si c’est le cas, on retourne le premier élément de cette liste et en prenant soin de l’enlever, comme ça, l’appel suivant à pop va retourner le token suivant. Si cette liste est vide, alors on délègue au lexer.
Conclusion
Dans ce post, j’ai présenté rapidement et sans trop entrer dans les détails quelques techniques de lexing que j’ai utilisé dans Litil. Ce n’est en aucune façon la meilleure façon de faire ni la plus performante. C’était plus une implémentation relativement facile à coder et à étendre tout en restant raisonnable pour tout ce qui est consommation mémoire (le fait de ne pas lire la totalité du fichier dans une seule String d’un coup par exemple).
Il faut aussi noter que c’est la partie la moins marrante à coder dans un langage. J’ai même été tenté de la faire générer par un outil comme AntLR ou SableCC, mais au final j’ai décidé de rester fidèle à ma vision de vraiment tout coder à la main (sauf les parties que je ne coderai pas à la main, NDLR).
Maintenant que cette partie est derrière nous, nous allons enfin pouvoir attaquer les sujets intéressants, e.g. le parseur et l’évaluateur, dans les posts suivants.
Post original


