
Mistral AI – Présentation et utilisation du modèle dans le vent

Introduction
On parle beaucoup d’IA (Intelligence Artificielle) générative ou LLM, surtout depuis que ChatGPT a fait son apparition. Dans cet article je vais vous présenter Mistral AI, un prétendant avec de sérieux arguments. Dans cet article nous allons voir comment l’utiliser et avec quels outils.
Mais c’est quoi déjà un LLM ?
Les grands modèles de langage (Large Language Models) sont des modèles d’apprentissage automatique capables de comprendre et de générer des textes en langage humain. Ils fonctionnent en analysant des ensembles de données linguistiques massives.
Pour qui ?
Les IA génératives ont beaucoup d’applications possibles, de l’informatique à la cuisine en passant par la création d’histoires pour enfants et tant d’autres… Si on se concentre sur le développement informatique, ces IA peuvent permettre :
- L’apprentissage de nouveaux langages
- Génération de code source
- Explication de morceaux de code
- Réponses à des questions précises (encore plus qu’une documentation)
- Et plus encore
Elles peuvent donc s’adresser à des publics aussi divers que variés, professionnels ou non.
Pourquoi Mistral AI ?
Mistral AI est une IA générative, tout comme ChatGPT, avec une première différence majeure : contrairement à ChatGPT qui est sous licence propriétaire et dont on ne sait pas ce que deviennent nos données, Mistral AI est sous licence ouverte (Apache 2.0) et est généré à partir de modèles ouverts également.
Plus d’information à ce propos sur ce billet de l’entreprise (en Anglais) : https://mistral.ai/news/about-mistral-ai/
Le second avantage est que, contrairement à ChatGPT, Mistral AI peut s’installer sur un ordinateur ou serveur local, complètement coupé d’internet. Pratique pour les entreprises ou les personnes soucieuses du destin de leurs données mais aussi en cas de problème ou d’absence de connexion (comme dans le train ou dans les zones blanches par exemple).
Un peu d’historique
Mistral AI est une solution jeune. L’entreprise à été créée en avril 2023 par 3 français : Arthur Mensch, Guillaume Lample et Timothée Lacroix. Ces trois personnes ne sont pas novices sur le sujet. Arthur Mensch à travaillé pour DeepMind, le laboratoire lié à l’IA de Google, tandis que ses deux compères ont travaillé chez Meta.

Crédits : David Atlan
Après une levée de fonds de 385 millions d’euros en décembre 2023, l’entreprise serait valorisée à 2 milliards d’euros actuellement, ce qui en fait une “licorne” parmi les startups françaises.
Comparaison et performance
Le premier modèle proposé, “Mistral Instruct 7B Q4”, contient 7 milliard de paramètres (B pour Billion en anglais). Cela peut paraître beaucoup, mais c’est au contraire un poids plume face à la concurrence (voir l’article sur leur site : https://mistral.ai/news/about-mistral-ai/).
En effet, malgré sa taille réduite, il surpasse le modèle “Llama 2 13B” sur tous les tests, ainsi que le modèle “Llama 1 34B” sur la plupart des tests.
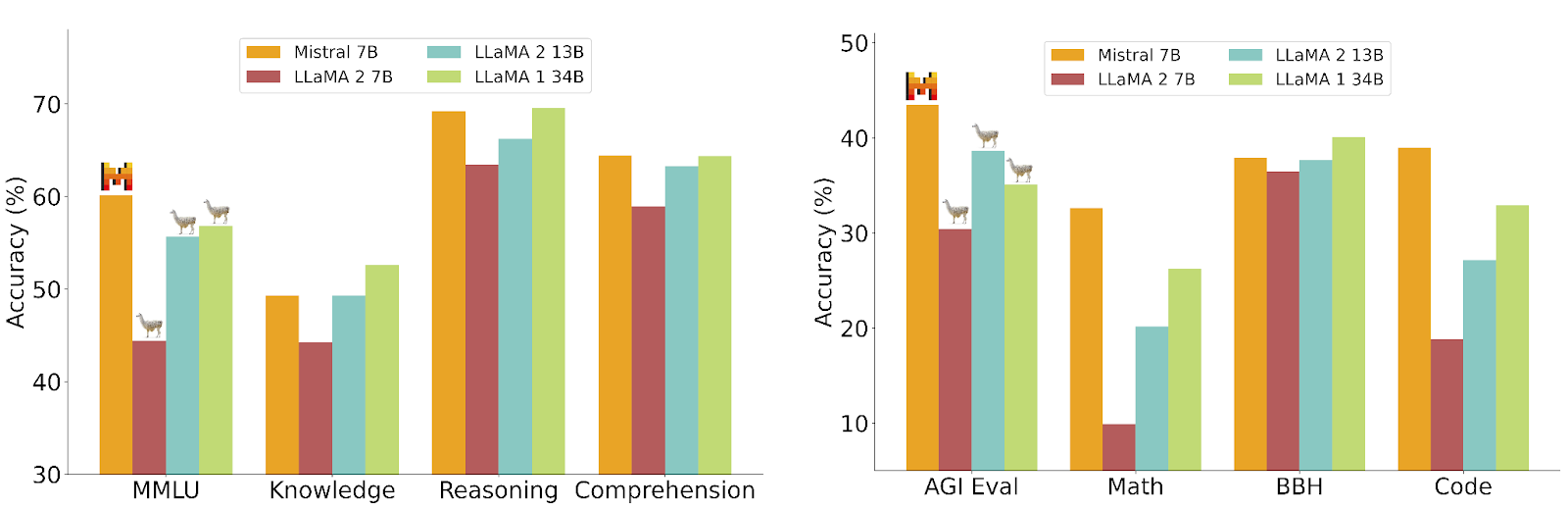

Source : https://mistral.ai/news/announcing-mistral-7b/
En décembre 2023, l’entreprise sort également un modèle nommé “Mixtral 8x7B” utilisant 46,7 milliards de paramètres et surpassant, d’après les tests de ses développeurs, le modèle “LLama 2 70B” de Meta à 70 milliards de paramètres et rivalise ou dépasse ChatGPT 3.5. L’architecture utilisée est appelée MOE pour “Mixture Of Experts”. Un expert étant une couche ou une sous-couche d’un réseau de neurones spécialisé dans un domaine. L’objectif est d’améliorer les performances du modèle, tout en réduisant les capacités de calculs nécessaires à leur entraînement et à leur inférence.
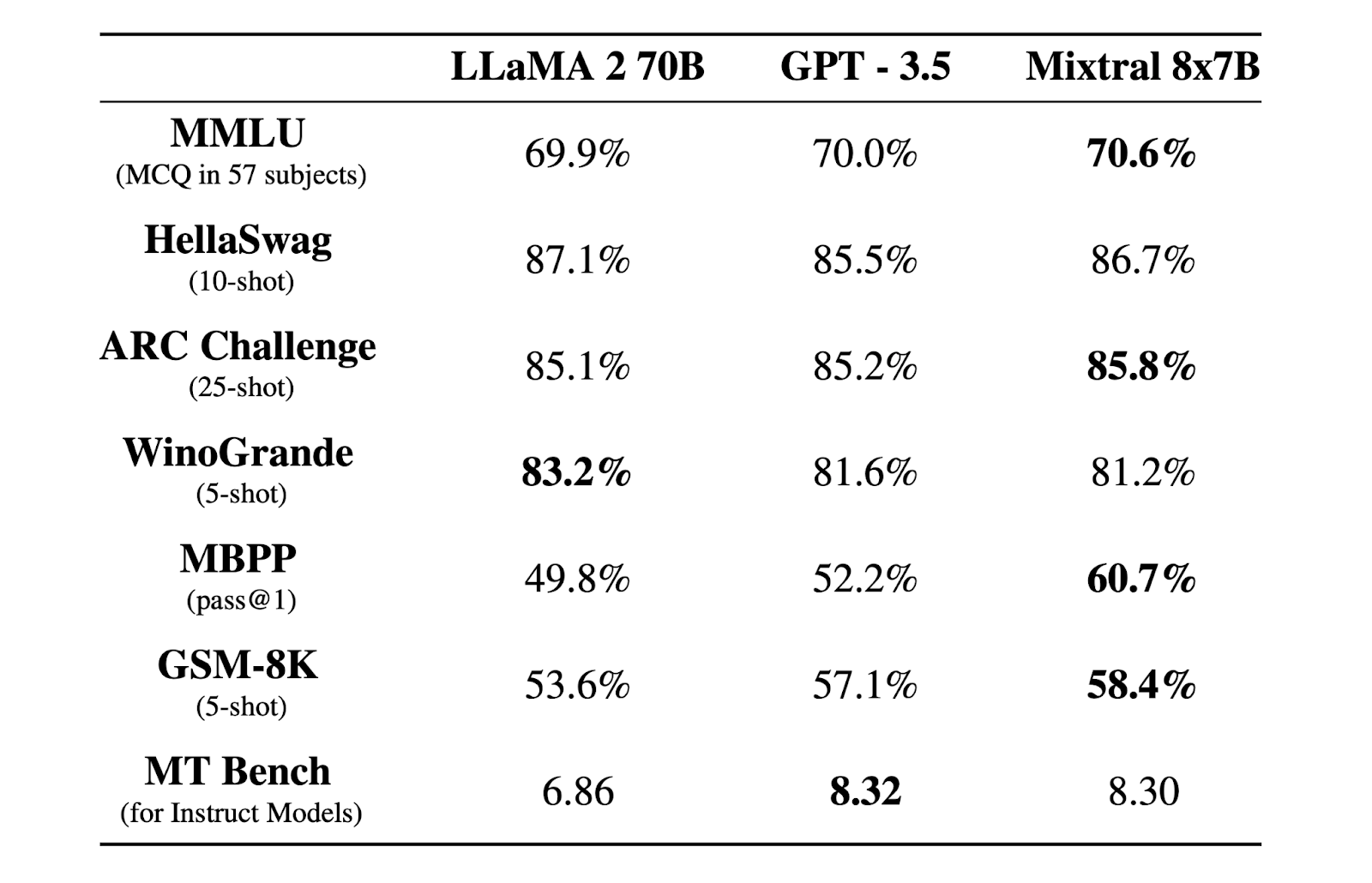
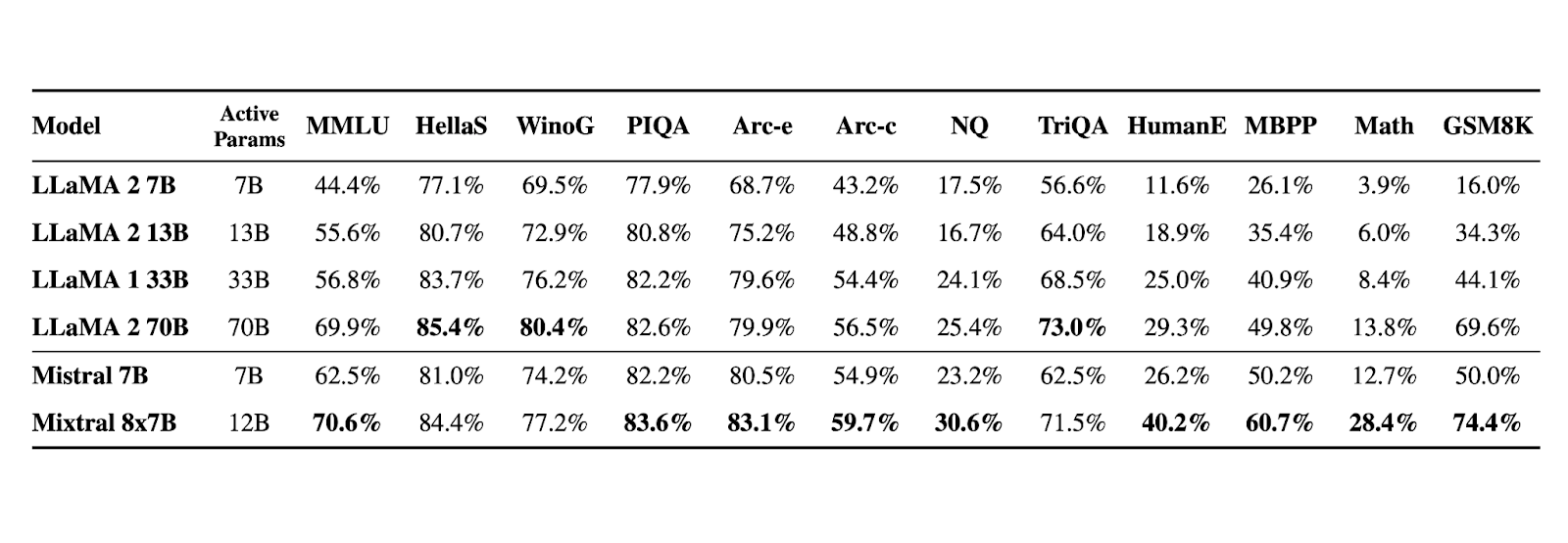
Source : https://mistral.ai/news/mixtral-of-experts/
Token ? Kesako ?
Les tokens sont des mots ou morceaux de mots utilisés par les LLM. En anglais par exemple, un token représente environ 4 caractères ou 0.75 mots. L’ensemble du travail de Shakespeare représente ainsi environ 900 000 mots ou 1.2 millions de tokens.
La vitesse de traitement est généralement indiqué en nombre de tokens par secondes. Plus ce nombre est élevé, plus la réponse est rapide à générer par le LLM.
Mise en place
Maintenant que les bases sont posées, passons à la pratique 🙂
Différentes solutions possibles
Georgi Gerganov a publié llama.cpp, une implémentation optimisée en C++ de Llama, le moteur de Meta. Il est capable de faire tourner la plupart des modèles, dont celui de Mistral AI. Différents outils en ont découlé, et les plus connus actuellement sont :
Interfaces graphiques
LM Studio et Jan sont deux solutions simples d’accès.
LM Studio
Il suffit de télécharger la version correspondant à votre système d’exploitation (compatible MacOS, Windows et Linux) et de lancer l’application.
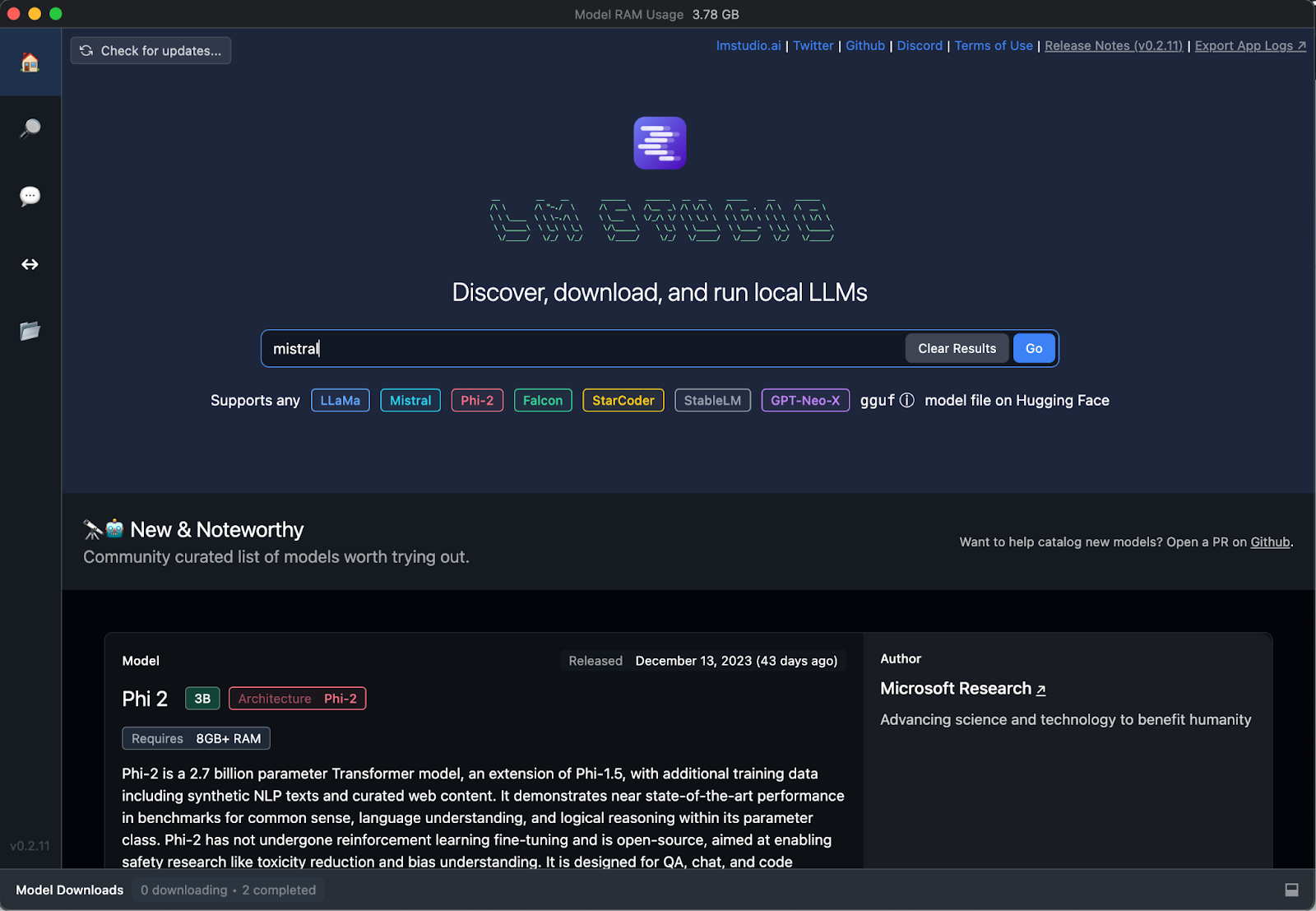
La première étape à effectuer est de télécharger le modèle voulu. Tapez “Mistral” puis cliquer sur “Rechercher”. Sélectionnez ensuite le modèle “mistral-7b-instruct-v0.1.Q4_0.gguf” et attendez la fin du téléchargement.
Vous pouvez alors passer dans l’onglet “AI Chat” (la bulle à gauche) où il faudra sélectionner le modèle téléchargé en haut de la fenêtre
Vous pouvez alors commencer à dialoguer avec votre assistant.
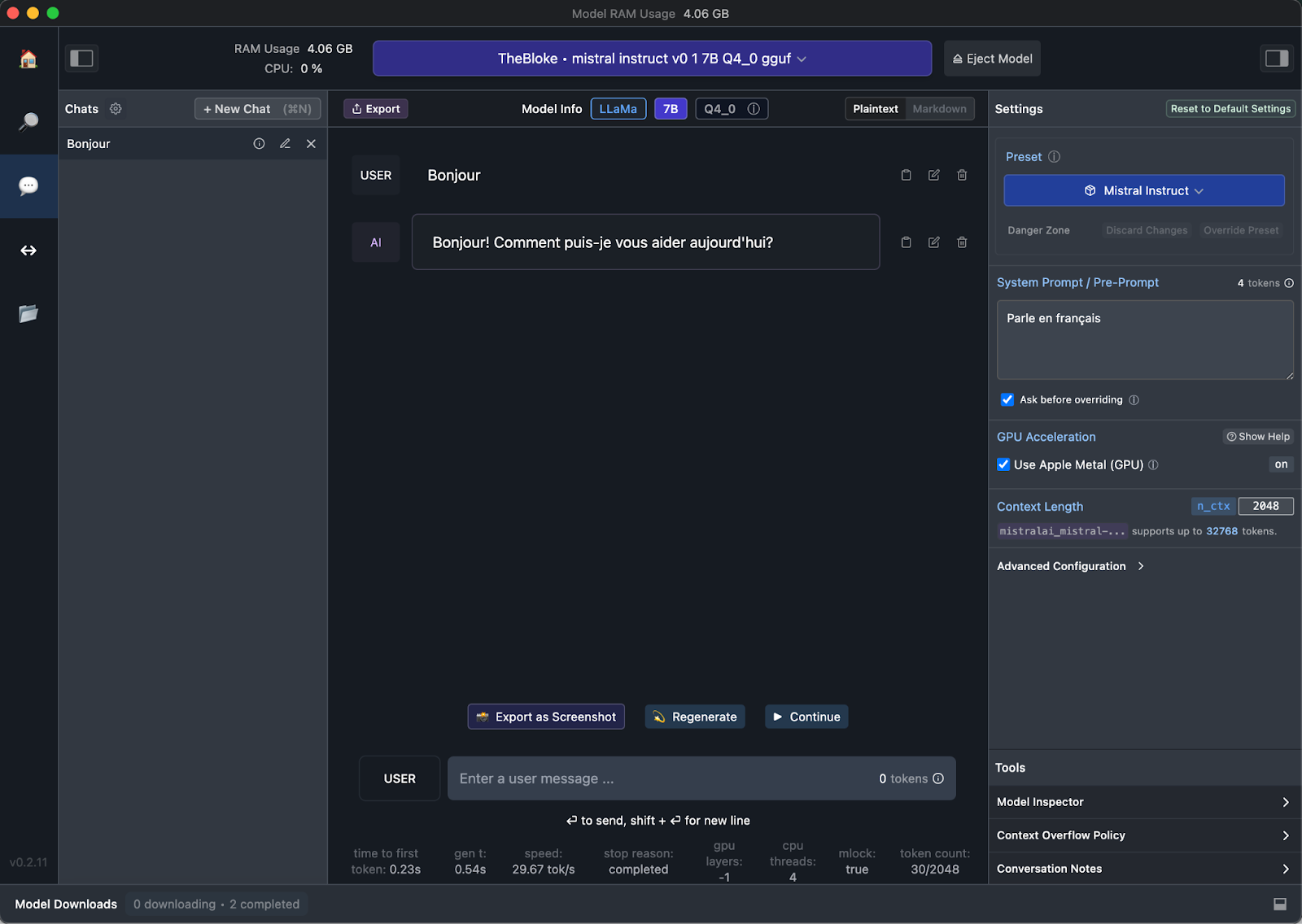
Vous pouvez également cocher l’option “Use Apple Metal” qui est encore expérimental mais fonctionne correctement (pour mes tests) et soulage le CPU.
Site : https://lmstudio.ai/
Jan
Comme le précédent, il suffit de télécharger la version correspondant à votre système d’exploitation (compatible MacOS, Windows et Linux) et de lancer l’application.
Ici le Modèle Mistral “Mistral Instruct 7B Q4” est le premier proposé, et il faut également le télécharger d’abord.
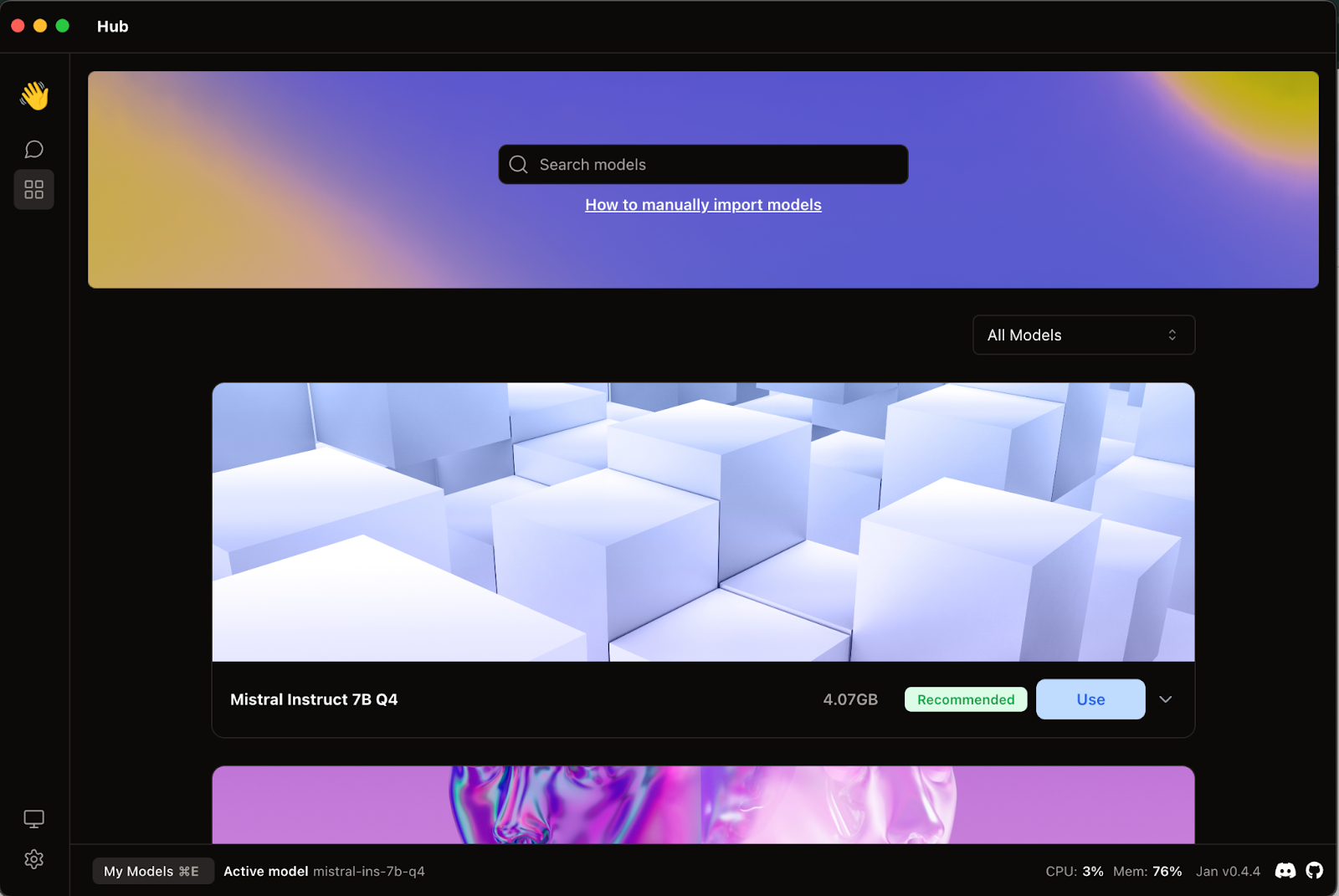
Vous pouvez alors aller à l’onglet “Thread” (la bulle également) pour commencer à dialoguer avec l’assistant :
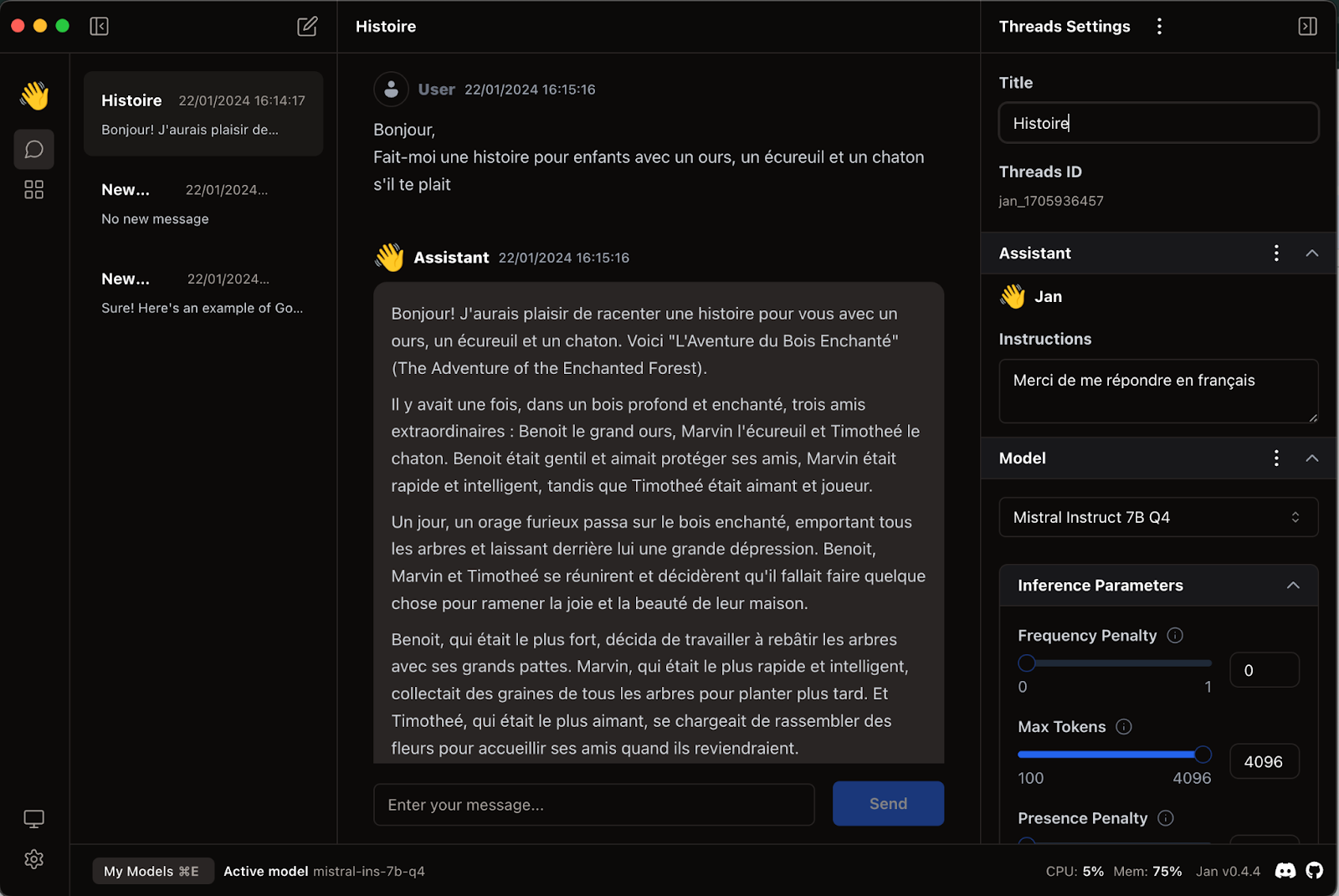
Site : https://jan.ai/
Différences
LM Studio semble le plus utilisé actuellement, avec beaucoup d’options paramétrables, dont l’utilisation du GPU. Malheureusement, s’il est gratuit pour une utilisation personnelle, il faut contacter l’équipe commerciale si c’est pour une autre utilisation.
Jan est quant à lui open-source et gratuit, mais un peu moins rapide avec plus d’utilisation CPU. Il possède par contre une API comme celle de ChatGPT, même si celle-ci est encore incomplète comparé à ce dernier.
Les réponses diffèrent légèrement d’un logiciel à l’autre, même si les deux solutions proposées sont correctes à chaque fois.
Autres solutions ?
Il existe d’autres méthodes pour tester Mistral AI via la ligne de commande ou en serveur web. Les solutions suivantes sont listées à titre indicatif mais ne seront pas détaillées dans la suite de l’article. Sachez juste qu’elles existent, et sont privilégiées pour une exposition sur un serveur
llama.cpp
Implémentation open-source en C++ du moteur Llama de Meta, c’est la solution la moins accessible. En effet, il faut pour cela récupérer le code source de ce dernier et le compiler. Il est alors accessible en ligne de commande. Même si ce n’est pas le plus compliqué à réaliser, cela peut rebuter les novices.
De plus, chaque requête est demandée indépendamment, ce qui est moins pratique qu’une conversation pour affiner nos demandes.
Code source : https://github.com/ggerganov/llama.cpp
Ollama
Permet de converser avec l’IA de manière conversationnelle en ligne de commande. Il existe un installeur pour Mac OS, ainsi qu’un script d’installation pour Linux.
Ce dernier peut également être interrogé via une API.
Site : https://ollama.ai/
Ollama-webui
Couche web de Ollama qui permet de converser avec un client web. C’est un projet open-source disponible en image Docker prête à être déployée : https://github.com/ollama-webui/ollama-webui. Avantages :
- Gestion des modèles
- Gestions des utilisateurs (avec RBAC)
- API compatible Open AI (ChatGPT)
text-generation-webui
Projet open-source, il permet de créer un serveur web pour gérer ses modèles (dont Mistral AI) et discuter avec ces derniers. Avantages :
- Gestions des modèles
- Paramétrage très complet
- Création de profils d’IA
- API compatible Open AI (ChatGPT)
Il possède un script d’installation/démarrage pour Mac OS, Linux et Windows.
Site : https://github.com/oobabooga/text-generation-webui
Performances
La plupart des tests ont été effectués sur un Macbook Pro avec puce M3 Pro, et je n’ai rencontré aucun problème de performance sur ce dernier (c’est presque normal me direz-vous) pour le modèle “mistral-7b-instruct-v0.1.Q4_0.gguf”.
A titre de comparaison, j’ai effectué les mêmes questions sur un Intel i7 de 11è génération (i7-11700) et même si les réponses générées sont les mêmes, il faudra être un peu plus patient car le temps de génération des réponses est beaucoup plus lent (9 tokens/secondes contre 20 à 30 sur Macbook).
On peut noter pour ceux qui ont un maximum de mémoire vive que le nouveau modèle “Mixtral 8x7B Instruct Q4” est également disponible, et promet des réponses encore plus précises.
Je n’ai malheureusement pu le tester que sur le PC avec un i7 car il demande plus de 30Go de mémoire vive pour fonctionner. Il demande également plus de puissance de calcul, car les performances tombent entre 2 et 4 tokens par seconde et certaines réponses s’arrêtent en cours.
Limitations
Malgré les instructions de départ pour lui demander de répondre en français, l’assistant répond souvent en anglais.
Il faut toujours avoir un œil critique sur ce qui est affirmé par l’assistant. Vous pouvez par exemple le contredire et il s’excusera alors en réaffirmant vos propos même si ces derniers sont faux.
Pour aller plus loin
Pour ceux qui sont intéressés par le moteur et qui n’ont pas besoin du côté hors-ligne, une offre est disponible et hébergée par leur serveur. Le coût d’exécution est moins important que pour ChatGPT :
Mistral AI API :
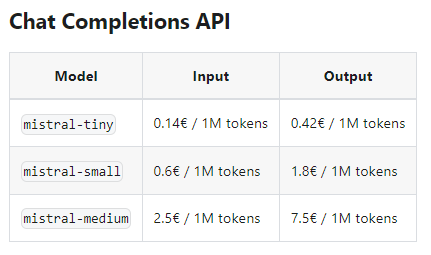
Les modèles correspondes à :
- tiny : Mistral 7B Instruct v0.2
- small : Mixtral 8x7B
- medium : le nouveau modèle le plus évolué. C’est un prototype, il n’est pas disponible hors-connexion.
ChatGPT API :
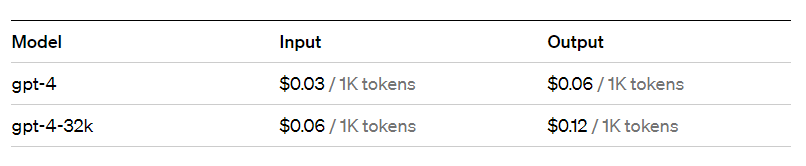

Conclusion
Mistral AI est une alternative intéressante à ChatGPT et répond aux deux principaux problèmes que sont la propriété intellectuelle et l’externalisation des données. Les solutions présentées sont encore jeunes, mais cela ne doit pas vous empêcher de les utiliser, bien au contraire !
J’espère que cet article vous aura donné envie d’essayer par vous même. Je suis convaincu que la productivité ne peut qu’être augmentée grâce à ces outils, et les DSI n’ont plus de raisons de les bouder 🙂
Références
- Mistral AI : https://mistral.ai/
- ChatGPT : https://chat.openai.com/
- Wikipedia : https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Accueil_principal
- Interfaces :
- LM Studio : https://lmstudio.ai/
- Jan : https://jan.ai/
- llama.cpp : https://github.com/ggerganov/llama.cpp
- Ollama : https://ollama.ai/
- Ollama-webui : https://github.com/ollama-webui/ollama-webui
- text-generation-webui : https://github.com/oobabooga/text-generation-webui


