
Découverte d’eBPF
En tant qu’utilisateur de Linux, il est possible que la seule chose qui vous intéresse soit l’inclusion de la dernière version des drivers de votre matériel dans le noyau. Pourtant, c’est loin d’être le seul pan du kernel qui évolue ! Ce sont notamment des évolutions du kernel (namespace, cgroups, …) qui ont permis de développer les conteneurs logiciels tels que Docker. Dans cet article, je vous propose de découvrir une autre innovation majeure du kernel : eBPF (ce n’est pas moi qui le dis, mais The New Stack).
Historique
Historiquement, lorsqu’on souhaitait faire de la capture réseau sous Unix, cette opération était réalisée dans l’espace utilisateur (c’est à dire en dehors du kernel). En général, lorsqu’on souhaite capturer du trafic réseau pour identifier un problème, on ne veut pas l’ensemble du trafic, mais on souhaite filtrer selon certains critères (protocole, destination…). Pourtant en pratique, cela nécessitait de copier l’intégralité des paquets depuis le kernel vers l’espace utilisateur avant même de déterminer si un paquet était intéressant à conserver pour une session particulière de capture.
Ainsi en 1992, Steve McCanne et Van Jacobson ont publié l’article : The BSD Packet Filter: A New Architecture for User-level Packet Capture. Celui-ci introduit BPF et propose une nouvelle architecture pour la capture de paquets en espace utilisateur. Celle-ci repose sur une machine virtuelle à registres qui fonctionne dans le kernel et permet d’évaluer les règles de filtrage des paquets sans recopie des paquets. Ce mécanisme, nommé BPF, a été intégré au noyau Linux en 1997 dans la version 2.1.75. Il est disponible sur la plupart des Unix et est utilisé par des outils standards comme tcpdump pour sélectionner les paquets à capturer. À ce moment-là, la machine virtuelle BPF est assez limitée : elle ne comporte que 2 registres 32 bits, une pile de taille minimaliste et ne supporte que les sauts vers l’avant.
En 2012, une évolution de bpf est proposée afin de sécuriser et filtrer certains appels systèmes en attachant à leur appel un programme bpf permettant d’évaluer le contexte et de permettre ou interdire l’appel comme cela était fait pour le traitement du trafic réseau.
Mais l’évolution majeure arrive en 2013, Alexei Starovoitov propose alors Extended BPF. Voici un résumé de ces évolutions :
- Un vérifieur qui s’assure que le code est sûr :
- pas de boucles infinies
- pas d’utilisation de pointeurs non vérifiés
- …
- Un compilateur JIT pour transformer le programme BPF en code natif
- L’extension des capacités de la machine virtuelle :
- passage de 2 registres 32 bits à 10 registres 64 bits
- possibilité d’appeler certaines fonctions du kernel

Par la suite, d’autres fonctionnalités seront encore intégrées :
- utilisation de maps pour l’échange d’information entre le programme bpf et l’espace utilisateur,
- la possibilité d’instrumenter encore plus d’événements du kernel avec des programmes bpf
- …
Ces nouvelles fonctionnalités sont particulièrement intéressantes, car elles introduisent de nouveaux usages d’eBPF autres que ceux d’origines liés au réseau. Il va notamment être utilisé pour filtrer les appels systèmes accessibles aux processus avec seccomp-bpf ou ajouter du tracing sur les appels systèmes et autres événements du kernel.
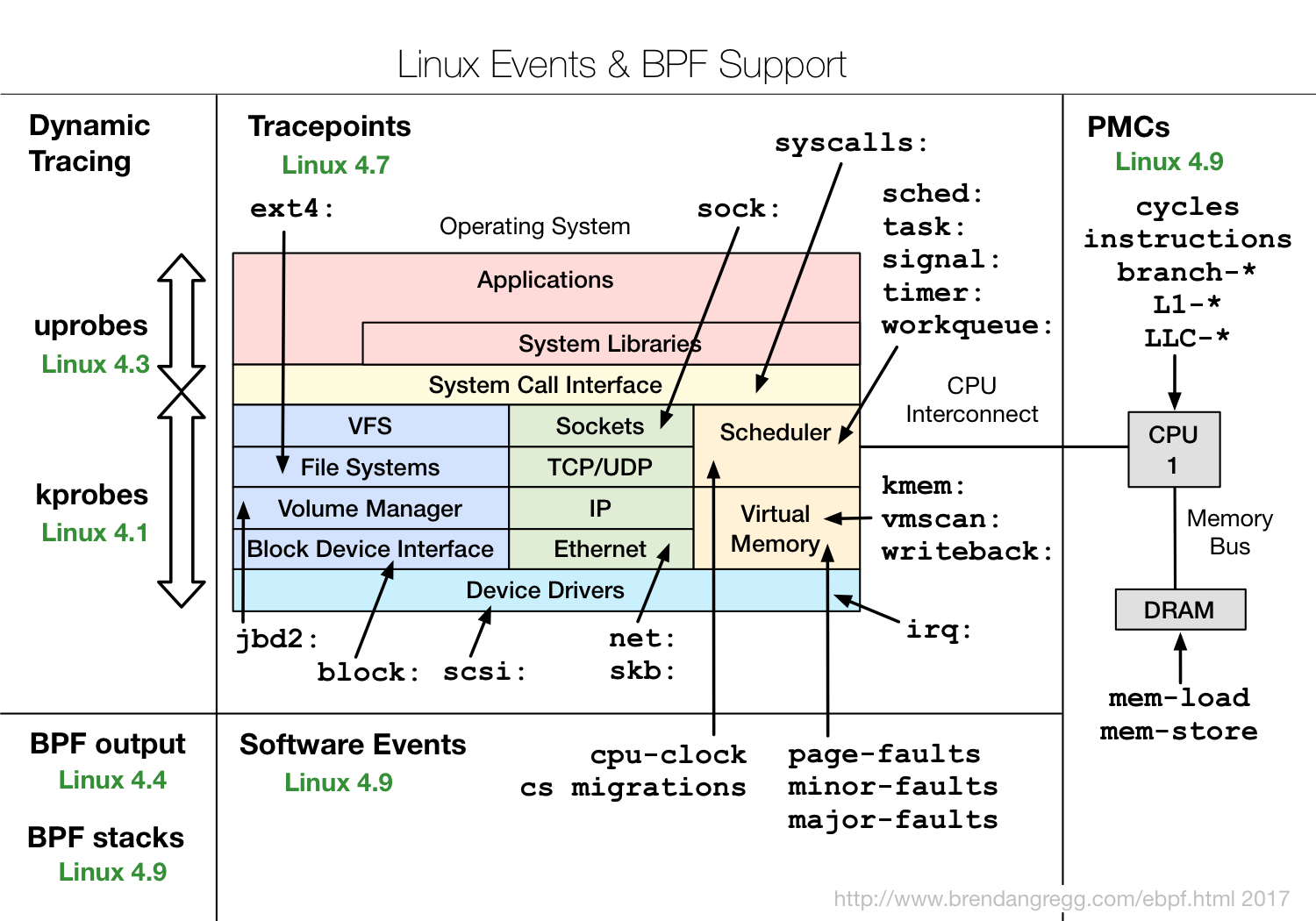
Pour une liste complète, n’hésitez pas à vous référer à la page de Brendan Gregg sur le sujet. En particulier, ce schéma.
Pour résumer, BPF est l’appellation d’origine. Linux a introduit l’appellation eBPF et pour différencier cette version de l’ancienne parfois nommée cBPF. Donc :
- lorsqu’on vous parle de cBPF, c’est sans les extensions,
- lorsqu’on vous parle d’eBPF, il s’agit de la version moderne
- lorsqu’on vous parle de BPF ¯\_(ツ)_/¯
Principe
Maintenant qu’on en connaît un peu plus sur l’historique du projet, voyons comment il fonctionne…
Fonctionnement
Tout est basé sur un appel système :
#include int bpf(int cmd, union bpf_attr *attr, unsigned int size);
Le premier argument cmd indique l’action à réaliser, exemple : BPF_PROG_LOAD, pour charger un programme bpf. Le deuxième argument attr porte les paramètres de l’action à réaliser, sa structure dépend de la commande (valeur du premier argument). Le dernier paramètre size est la taille de la structure passée en deuxième argument.
Les programmes eBPF sont événementiels, c’est-à-dire que leur exécution est déclenchée en réponse à des actions ou appels de fonctions internes du kernel. Afin de conserver des données entre les différentes exécutions du programme, mais aussi afin d’échanger des informations entre le programme BPF qui tourne dans l’espace du noyau et l’espace utilisateur, eBPF propose d’utiliser des maps. Les autres commandes utilisables avec BPF sont dédiées à la création et à la manipulation de ces maps.
Mais avant d’aller plus loin, voyons comme sont chargés les programmes eBPF et comment ils sont reliés aux événements qui nous intéressent. Pour commencer, voyons le détail de la structure qui porte les paramètres de l’appel à BPF_PROG_LOAD :
struct { /* Used by BPF_PROG_LOAD */
__u32 prog_type;
__u32 insn_cnt;
__aligned_u64 insns; /* 'const struct bpf_insn *' */
__aligned_u64 license; /* 'const char *' */
__u32 log_level; /* verbosity level of verifier */
__u32 log_size; /* size of user buffer */
__aligned_u64 log_buf; /* user supplied 'char *'
buffer */
[...]
};
- prog_type, permet d’indiquer le type de programme et par quel type d’événement il sera déclenché. Par exemple, pour attacher un programme à l’exécution d’une fonction on utilisera : BPF_PROG_TYPE_KPROBE.
- insn_cnt indique le nombre d’instructions du programme
- ìnsns pointe vers la liste des instructions
- license indique la license du programme
- les 3 attributs suivants (log_level, log_size et log_buf) permettent d’obtenir des informations sur le chargement du programme et le résultat du verifier.
À moins, que vous souhaitiez directement écrire le bytecode de votre programme, il sera préférable d’utiliser LLVM afin de transformer le code C en bytecode bpf. Vous utiliserez alors une commande du type :
clang -O2 -emit-llvm -c bpf.c -o - | llc -march=bpf -filetype=obj -o bpf.o
Une fois la structure correctement alimentée et l’appel système effectué, le noyau prendra en charge votre programme qui subira encore quelques manipulations/transformations :
- dans un premier temps, le verifier va s’assurer que le programme :
- ne comporte pas plus d’instructions que la limite (4096 en Linux 4.14)
- est un Diagramme orienté acyclique. C’est à dire, qu’il ne comporte pas de boucles.
- accède uniquement à des zones mémoires identifiées
- …
- ensuite, avant sa première exécution, le programme sera transformé de bytecode eBPF vers le code natif de la plate-forme pour les architectures supportées
BCC : BPF Compiler Collection
Tout cela peut sembler un peu compliqué à mettre en oeuvre. Heureusement, il existe un outil qui simplifie grandement l’utilisation d’eBPF : BPF Compiler Collection. Ce projet propose notamment un frontend python que nous allons utiliser pour mettre en oeuvre quelques exemples de programmes eBPF.
Pour commencer, assurez-vous d’avoir une machine linux avec un kernel récent ( =>4.15). Vous pouvez également utiliser vagrant avec le Vagrantfile disponible sur le repository github contenant les exemples de cet article.
Ensuite, installez les dépendances nécessaires (cette étape n’est pas nécessaire si vous utilisez vagrant) :
$ apt update $ apt install -y python python-pip bpfcc-tools
Pour tester avec un cas simple, créez le fichier first_trace.py ci-après.
Ce script python va créer et charger un programme eBPF à partir du code source passé en paramètre. Ce programme sera attaché au syscall clone qui est utilisé dès que l’on souhaite créer un nouveau processus.
#!/usr/bin/env python
import os
from bcc import BPF
print('Launching in background, pid: ', os.getpid())
# This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
BPF(text='''
int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, eBPF!\\n");
return 0;
}
''').trace_print()
Lancez ce script en arrière-plan avec la commande : sudo ./first_trace.py &
Il est nécessaire de le lancer en tant que root afin de pouvoir utiliser l’appel système bpf.
Vous pouvez éventuellement déjà voir des messages apparaître dès qu’un nouveau processus est créé. Vous pouvez également lancer le script ci-dessous qui créera un nouveau processus toutes les 3 secondes. Ce nouveau processus affiche un message et s’arrête.
#!/usr/bin/env python
import os
import time
def child():
print('New child ', os.getpid())
os._exit(0)
def parent():
while True:
newpid = os.fork()
if newpid == 0:
child()
else:
time.sleep(3)
os.waitpid(newpid, 0)
parent()
Voici un exemple de sortie de ce test :
vagrant@ubuntu-bionic:/vagrant/examples/01$ sudo ./first_trace.py &
[1] 8178
vagrant@ubuntu-bionic:/vagrant/examples/01$
('Launching in background, pid: ', 8179)
vagrant@ubuntu-bionic:/vagrant/examples/01$ ./clone.py
bash-8154 [000] .... 207.972080: 0x00000001: Hello, eBPF!
-8180 [000] .... 207.987895: 0x00000001: Hello, eBPF!
('New child ', 8181)
python-8180 [000] .... 210.990015: 0x00000001: Hello, eBPF!
('New child ', 8182)
python-8180 [000] .... 213.992402: 0x00000001: Hello, eBPF!
('New child ', 8183)
Une fois votre test effectué, lancez sudo kill <pid>, où vous remplacerez pid par l’identifiant du processus lancé en arrière-plan qui s’est affiché après son lancement.
Cas d’utilisation
La technologie eBPF est en plein essor, le fait de pouvoir exécuter du code en mode kernel intéresse beaucoup, d’autant plus qu’avec eBPF, il n’est pas nécessaire de recompiler le noyau ou d’être spécialiste du développement de modules pour pouvoir le faire. Ainsi, le projet est utilisé pour :
- De la capture d’événements du kernel, pour
- des mesures de performance
- du tracing
- Du filtrage réseau :
- haute-performance (anti-DDOS, …)
- avancé et dépendant du contexte
Conclusion
J’espère que ce petit tour d’horizon vous a donné envie d’aller plus loin. Si c’est le cas, n’hésitez pas à consulter les références que j’ai consultées pour le rédiger. Dans un prochain article, nous aborderons Cilium qui utilise cette technologie pour proposer une solution réseau multifacette dans le contexte des conteneurs et notamment Kubernetes.
Références
- Historique :
- Papier original par Steven McCanne et Van Jacobson : http://www.tcpdump.org/papers/bpf-usenix93.pdf et https://www.usenix.org/legacy/publications/library/proceedings/sd93/mccanne.pdf
- BPF – in-kernel virtual machine : http://vger.kernel.org/netconf2015Starovoitov-bpf_collabsummit_2015feb20.pdf
- Articles :
- What can BPF do for you ? : https://events.static.linuxfound.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf
- Awesome eBPF : https://github.com/zoidbergwill/awesome-ebpf
- How I ended up writing eBPF : https://bolinfest.github.io/opensnoop-native
- eBPF, past, present and future : https://ferrisellis.com/content/ebpf_past_present_future/
- eBPF, syscalls and map types : https://ferrisellis.com/content/ebpf_syscall_and_maps/
- Actualité :
- Documentation :
- https://en.wikipedia.org/wiki/Berkeley_Packet_Filter
- Documentation officielle BPF : https://www.kernel.org/doc/html/latest/bpf/index.html
- BPF and XDP Reference Guide : https://cilium.readthedocs.io/en/latest/bpf/
- Verifier : https://blogs.oracle.com/linux/notes-on-bpf-5
- Tracing :
- http://www.linuxembedded.fr/2019/03/les-secrets-du-traceur-ebpf/
- Java Flame graphs : https://www.youtube.com/watch?v=saCGp-T6saQ
- Jérémie Lagarde DevoxxFr : https://www.youtube.com/watch?v=rdrnHrQGQlw
- Liz Rice : https://www.youtube.com/watch?v=4SiWL5tULnQ
- Network :
- XDP : Netronome – https://github.com/Netronome/bpf-samples
- Cloudflare : https://blog.cloudflare.com/epbf_sockets_hop_distance/
- Facebook : http://vger.kernel.org/lpc_net2018_talks/ebpf-firewall-LPC.pdf
- Cilium : https://cilium.io/
- Calico : https://www.projectcalico.org/tigera-adds-ebpf-support-to-calico/
- Tcpdump : https://medium.com/@cjoudrey/capturing-http-packets-the-hard-way-b9c799bfb6
- Toward a faster Iptables in eBPF : https://webthesis.biblio.polito.it/8475/1/tesi.pdf
- Toward an eBPF-based clone of iptables :



{kind=link}